【概述】-Linux内核同步-内核锁
内核锁是内核同步的必不可少的方式,内核中的锁是多种多样,每一种锁都有着各自不同的使用场景。正确理解这些锁的实现原理、如何选择适用场景等等,这些都是Linux内核/驱动开发中必须掌握的基本知识点。
原子性
CPU的分类
在描述内核锁之前,必须先澄清一个基础概念,处理器可以根据指令集区分:RISC(简单指令集)、CISC(复杂指令集)。
在这两种不同的指令集上,执行同样的操作所需要指令数是不一样的,因此原子性是不一样的,那么,着对于加解锁的原理也就是不一样的。

左边:以X86为代表,CISC指令集是可以直接在内存上进行操作的,一条addl指令即可在一个“原子周期”完成一个整数的加法操作。但是前提是只有在“单核”上才能保证原子性,而“多核”时因为在内存上读写不是原子的,因此也就保证不了多核读写的原子性了。
右边:以ARM为代表,RISC指令集所有操作都必须在CPU内部进行,因此这里需要拆成3步,必须经过一个“读、修改、写”的序列操作才能完成这个加法,即有一个RMW的序列。
RMW可能引发的问题
RMW是一个专有名词,即“读、修改、写”,这个过程不是原子的,它有可能在中途被打断,因此执行结果就不一定符合预期了。
Tips:
哪怕是一个最简单的整数加减在硬件处理上都不是原子的。
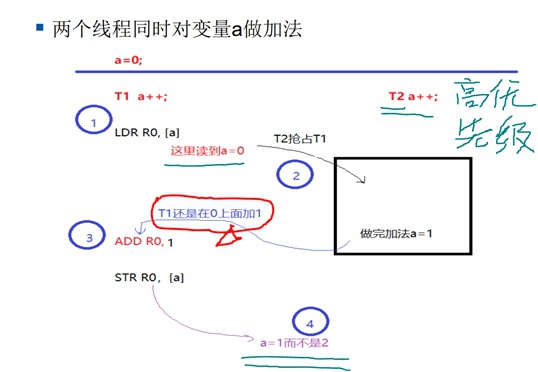
以上只是举了一个简单的例子,在工程中的现实例子是:驱动编程的时候,会遇到两个线程同时修改一个寄存器的情况,这也是一个RMW序列,因此也会有同样的竞争问题。
对于这个问题的解决办法:
- 一是软件处理,在代码中加spinlock锁保护。
- 二是硬件处理,在IC公司一般硬件工程师会问软件工程师“哪些寄存器”是需要“特殊处理”的,硬件上会将一个寄存器“分裂”成set(置为1)、clear(置为0)两个寄存器,然后由硬件去保证源寄存器修改的原子性。这样就免去了RMW这个序列的过程。
另外,在有些SOC上会使用“bitband技术”来确保原子性操作:
bitband是指比如一个寄存器有32bit,那么硬件会额外添加32个影子寄存器与这个32bit寄存器每1bit做映射。每个影子寄存器也是32bit的,当需要修改源寄存器某个bit时,可以修改对应的影子寄存器的对应bit即可,硬件会去确保修改的原子性。
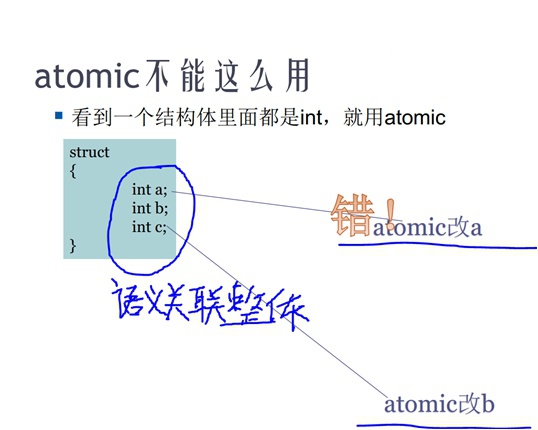
锁住语义整体
语义关联的结构,必须整体保持原子性,即需要整体加锁、解锁,而不能对其中某一个部分成员加锁,如下:
多核处理器竞态
上面一节介绍的是单纯的两个线程(TASK)之间的竞争关系,以及解决竞争的办法,但现实工程中,往往并不是单core处理器,也并不只有线程参与“临界区”访问,因此,竞争往往是非常复杂的。 本节就重点描述一下多core处理器下的竞态。
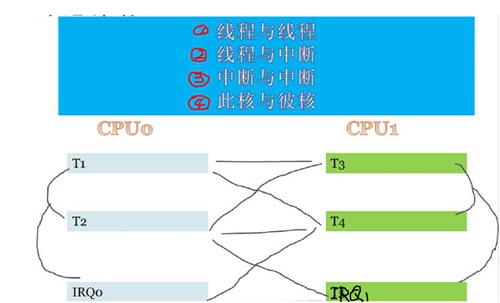
线程/中断竞争网络
如下图所示:这里线程、IRQ组成了一个非常严重的竞争网络,它们之间彼此状态都对于“临界区”存在影响。
竞争网络下的编程
在以上竞争网络下编程,总结起来最关键的往往是需要注意下面几点情况:
- 本核IRQ是可以屏蔽的,在什么场景下屏蔽,屏蔽多久是个经验活儿;
- 本核调度是可以禁止的,关闭本core调度并不影响其它core调度;
- 锁是可以保护“临界区”的,需要区分可锁“睡眠临界区”与不可锁“睡眠临界区”;
实际工程中解决竞争问题,往往是根据不同场景,将以上几点搭配来完成竞争同步操作。
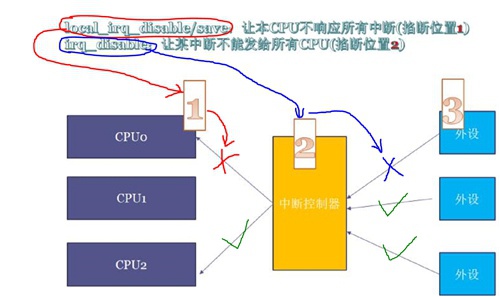
Linux Kernel中关闭中断的API从“发送”和“接收”两个方向有两类:
- 接收侧:针对CPU核,让local core不响应所有irq,如下图[1]位置
- local_irq_disable / local_irq_enable 不管core上irq的历史状态
- local_irq_save / local_irq_restore 保存core上当前irq状态,并恢复
- 发送侧:针对IRQ号,让某个irq不能发送给所有core,如下图[2]位置
- irq_disable / irq_enable
Tips:
需要注意的是,Linux Kernel中并没有一个API能让其它core不响应中断,只能不发给其它core
这里与其说是关闭调度,还不如放松一下条件,说成是关闭抢占。
因为直接关闭core上调度,有点儿太严苛了,某些能够锁住可睡眠临界区的🔒,是可以在占用期间被调度的。
而对于不能锁可睡眠临界区的🔒,只需要关闭抢占,然后让coder自己保证编码时不用在可睡眠临界区、也不用在主动schedule走的临界区即可。
加锁的原则是:同一把锁(功能)、语义整体(功能)、粒度最小(性能)。
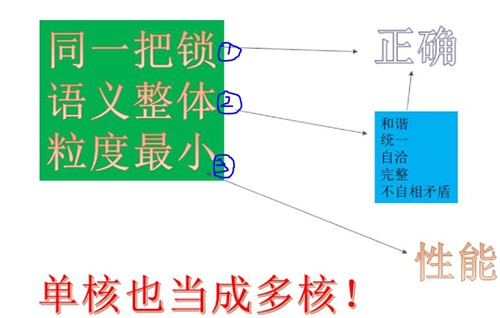
① 当加速的粒度很小导致没有锁住语义整体,可能会出现系统随机崩溃的bug,这时去做debug调试找root-cause是非常困难的。
② 当加锁的粒度很大时,虽然保证了语义整体但却锁住的资源范围很大,就可能会造成系统的性能低下。这时就需要修改软件的数据结构,从数据结构上去减小锁的粒度。
③ 至于同一把锁,傻子也能想明白的事情,我们就不多做阐述了。。。但是为了防止代码量很大时加锁混乱,可以有两种简单的办法去避免问题:一锁的名字与资源绑定,二从数据结构上锁与资源绑定;
各个锁具体见下面几节中:
- atomic
- spinlock
- mutex
- rwlock
- rcu
- ...
Atomic
排他性LDREX和STREX指令
LDREX和STREX指令是在V6以后才出现的,代替了V6以前的swp指令,可以让bus监控LDREX和STREX指令之间有无其它CPU和DMA来存取过这个地址,即看该地址内存独占标记是否被位置,若有的话,执行STREX指令时第一个寄存器里设置为 1(动作失败)。若没有,执行STREX指令的第一个寄存器里设置为0(动作成功)。
通过这两个指令做到原子性:
- LDREX:load并且设置内存独占标记
- STREX:store并且清除内存独占标记
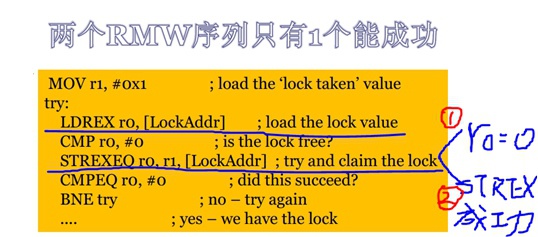
虽然它听起来很牛逼,但是由于应用场景仅限于锁住“一个”整数,而实际场景中绝大部分都不是一个单独的整数需要加锁、却是深度绑定在一起的各种语义整体需要一起加解锁。因此原子锁实际应用场景非常受限。
原子锁API
原子锁是Linux内核最底层的锁,它也是通过上面排他性load和store来实现的。下面列出了一些API接口:
void atomic_add(int i, atomic_t *v)
void atomic_sub(int i, atomic_t *v)
void atomic_inc(atomic_t *v)
void atomic_dec(atomic_t *v)Spinlock
自旋锁也是用到LDREX和STREX指令来实现的。在Linux内核中,spinlock应该是用的最多的一种锁了。下面看一下spinlock究竟对程序做了什么。
spinlock的原理
spinlock的工作原理可以简单用下图表述:
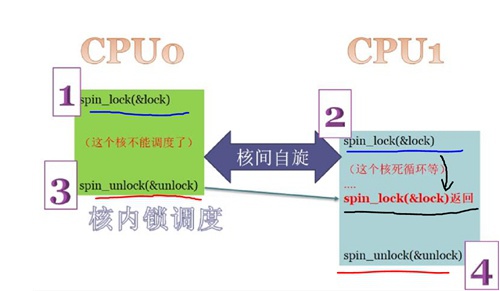
可以看出,它执行的工作逻辑是:
核内锁调度,核间自旋。因此,它的“自旋”只能在多核处理器中才会能体现出来,在单核中它只是简单的锁调度器。
具体间文章内核锁之-spinlock
它特别适用于锁那些时间特别短的区间,这个场景下,与其进行线程切换还不如使用spinlock原地踏步地去“忙等”。因为线程切换时,上下文切换也会花费大量cpu mips,可能还不如spinlock效率高。
spinlock使用注意点:
- 锁住的临界区不能睡眠!!! 因为一旦调度走,可能会造成系统hung死
- 同理锁住的临界区不能主动放弃CPU!!!
- 被spinlock锁住的区间是有可能被当前core上的irq直接打断的,因此当线程、中断都访问“临界区”时需要调用spinlock_irqsave(禁止当前core的中断、调度)来保证排他性!!!
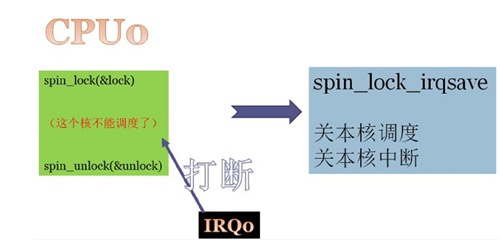
使用spinlock消除多核竞态
针对前面章节中提出的多核竞争网络,是可以通过spinlock彻底消除的,因为spinlock有API可以同时满足三点:关中断、关调度、加锁
在线程TASK里面统一调用spin_lock_irqsave,在中断IRQ处理函数handler里面统一调用spin_lock。
Tips:
在Linux里面需要把平台看成是多核的,即便是单核也想象成是多核的,因为Linux强调驱动跨平台性,驱动与硬件平台体系架构是无关的
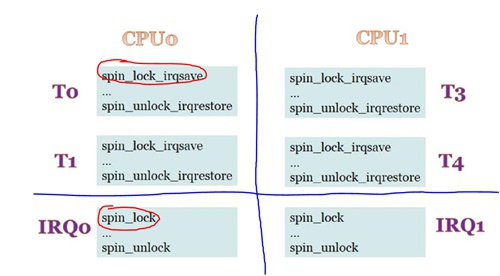
- 核内:
- Task0 <==> Task1:因为“关调度”而不会进行线程切换,消除Task间竞争;(这里或者说成是“关抢占”更合适一些,因为主动放弃cpu或者sleep时还是会被调度走,这是不允许的)
- Task0 <==> IRQ0:因为“关中断”而不会被中断打断,消除Task和Irq间竞争;
- 核间:
- Task0 <==> Task3:因为“spin_lock”而忙等,消除Task间竞争;
- Task0 <==> IRQ1:因为“spin_lock”而忙等,消除Task和Irq间竞争;
- IRQ0 <==> IRQ1:因为“spin_lock”而忙等,消除Irq间竞争;
Tips:
对于ARM处理器,这里会有一个问题,因为ARM上除了Timer等一些中断,其余绝大部分中断都是Core0处理、并通过Core0转发的
一旦Core0上irq-handler里面拿了spin_lock,同时它被其它core线程的spin_lock_irqsave给block住的话
如果占有spinlock的其它core线程不及时释放锁,就有可能造成Core0上不响应任何中断了!!!系统有可能就进入一个lockup状态!!
spinlock的API与关中断
下面这个表格对比了两个spinlock的API与local_irq_disable对于多核上“关中断”、“关调度”上的区别
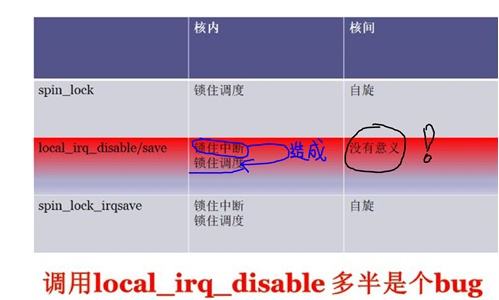
local_irq_disable这个API是非常有风险的,因为它只关闭本核的中断/抢占,无法组织其它核上irq访问临界区的。
Mutex
不仅是自旋锁,信号量也是利用LDREX和STREX指令来实现的。
但是mutex与spinlock的主要区别就在于,拿mutex的线程是可以睡眠和被调度的,它不锁调度。
mutex的原理
它的原理非常简单,正如前面描述的,拿不到mutex的线程去睡眠被调度出去,等mutex被释放后,等待的线程被唤醒继续跑。

具体间文章内核锁之-mutex
RWLock
读写锁,又叫读写自旋锁。
rwlock的原理
TODO...
具体间文章内核锁之-rwlock
RCU
TODO...
RCU的原理
TODO...
具体间文章内核锁之-RCU
🔒调试
Lockup Detector
是Linux内核的“死锁检测”机制,目的是检测调度/中断是否出现死锁,它可以在defconfig中选择开启和关闭,一般在工程调试阶段为了方便一定是需要打开的:
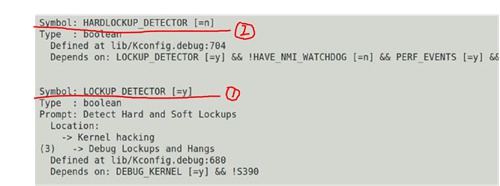
它的源码路径在:
/kernel/kernel/watchdog.cSoft Lockup与Hard Lockup
-
soft lockup:*锁住了调度器*
当出现soft lockup时,该core就不能再调度了,只能当前这一个线程在上面跑了,其它线程都无法被调度到该core上了。
比如,调用spin_lock()的线程出现bug时,此时就是调度被关闭了,但是注意此时中断还是可以入该core执行的。 -
hard lockup:*锁住了中断*
当出现hard lockup时,该core的中断被关闭了,此时调度也被动被关掉了,这时该core不但不能切换连timer等中断都无法进入该core了,基本等同于该core已经hang死了。
比如,当调用spin_lock_irqsave()/local_irq_disable()的线程出现bug时,就是关中断、关调度。

① 创建:一个高优先级的RT线程,该线程会周期性的睡眠、唤醒,每个“一定时间”被唤醒后会把一个计数器+1
② 创建:一个定时器中断,定时器超时会触发中断,去检测上面这个计数器是否已经+1
③ 检测:
- 当出现soft lockup时,因为该core上的调度器被锁导致RT线程无法被执行
- 因此,当定时器中断触发之后就会发现以上计数器X秒没有被+1,然后相隔一定时间(可配置,默认20s)就会去打该core上的backtrace。
① CPU自带NMI能力,一般是用SOC上PMU单元(电源管理单元)配置成周期性的去产生中断,该NMI中断是“不可屏蔽中断”,是无法被关闭的
② 检测:
- 对于hard lockup,因为已经对“可屏蔽中断”都不响应了,就无法通过timer中断去检测死锁了。只能通过NMI去处理;
- 当NMI中断被处理时,会检测到哪里将中断block住了,并打印出信息。
一般情况下,ARM是只支持soft lockup检测的,不支持hard lockup检测,因为arm中没有支持NMI中断。
ARM如果需要支持NMI中断,必须有一些很特殊的手段:
- Linaro做了一个补丁:
用fiq去模拟NMI,需要将内核树打上这个补丁才行。
具体见“精品转载”中《hardlockup-detector-FIQ-watchdog》 - 另一个补丁:
用其它core去读被hard lockup的core,这样互检也能检测出来,但是无法做栈回溯,因为跨核看不到栈
以上两个补丁目前都没有被Linux Kernel主线接受。
具体见“精品转载”中《hardlockup-detector-secondary-cpu》
参考文档
赞一个
b不过有一个地方不太对吧PMU (Performance Monitoring Unit),不是电源管理单元