【概述】-Linux内核三驾马车之-IO管理
IO是Linux内核里面除了进程管理、内存管理之外另一个比较重要的概念。IO涉及的知识覆盖面会非常宽泛,从用户态编程框架模型、到内核系统调用、文件系统、io调度、磁盘驱动、网络驱动等等。IO对于系统的影响,个人理解其实更多的体现在性能方面,并且其中涉及纯软件编程方面的内容会比较多一些。
IO模型
模型分为:阻塞IO、非阻塞IO、多路复用IO、SignalIO、异步IO、Libevent等等,这些不同的IO模型有不同的适用场景,IO模型的选择会深刻影响到系统性能。
比如,阻塞/非阻塞/异步IO适合块设备(磁盘),其它更多的是适合字符设备/socket等(因为主要是监听事件)。
Tips:
但是,对于监控磁盘中file的变化,可以使用inotify机制,也是事件通知。
它这里就很类似于字符设备,可以用到几乎所有的IO模型了。
它可以监控的状态有:
IN_ACCESS - 读取文件
IN_MODIFY - 修改文件
IN_ATTRIB - 修改文件属性
IN_OPEN - 打开文件
IN_CLOSE_WRITE - 被打开为“可写入”状态的文件遭关闭
IN_CLOSE_NO_WRITE - 被打开为“非写入”状态的文件遭关闭
IN_MOVED_FROM && IN_MOVED_TO - 文件被移动或者更名
IN_DELETE - 文件或目录被删除
IN_CREATE - 被监控的目录下有新文件产生
IN_DELETE_SELF - 被监控的文件遭删除
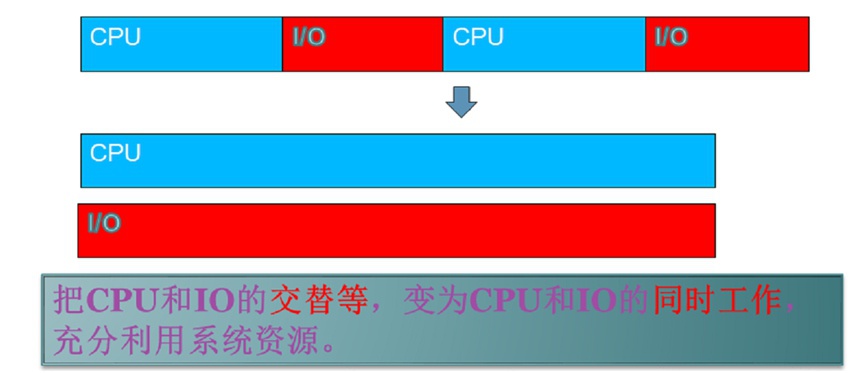
红蓝图
标记CPU与IO占用时间分布情况的图形,蓝色的标识CPU耗时阶段,红色的标识IO耗时阶段,如下所示

关键问题
CPU与IO需要并行问题源于:CPU与IO是分属于不同硬件的,两者互不干扰。
将二者并行操作,能最大程度的充分利用硬件资源、节省时间。做软件的比较忌讳的是CPU等IO、IO等CPU这类互等的场景,从红蓝图上直观来看,比较好的系统状态是红/蓝并行,让“红的更红、蓝的更蓝”。
①阻塞IO
最简单的IO模型,进程调用此类API时会被阻塞住等待IO完成才能继续执行。
阻塞IO的两个问题:
- IO完不成,那么程序就退不出来,它需要顺序执行、并不适合并发场景。
- 为了解决这个问题,早期编程模型中,会创建出很多进程/线程来单独处理每个阻塞IO,而它带来的问题却是进程/线程都会有不小的CPU开销,这样整个系统的性能不会太好。
- IO可能会被信号打断。被信号唤醒后,内核正在执行的相关IO函数中会有分支去调用signal_pending()检测信号。
- 检测到就返回-ERESTARTSYS给内核处理,内核看到-ERESTARTSYS就知道是阻塞IO被信号打断了。
- 而被信号打断的阻塞IO可能返回用户态(返回值-EINTR)、也可能不会返回到用户态,取决于信号处理是否设置sa_flag中有标记SA_RESTART,设置的话该系统调用会被linux内核自动重新触发(有一些系统调用是不支持自动重发的,可以查看signal的man page)。
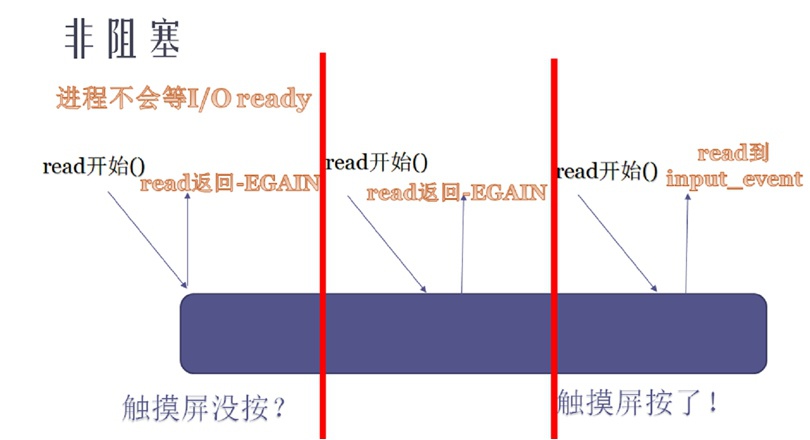
②非阻塞IO
纯粹的非阻塞基本是不用的,它的原理是:当应用发起一个IO时,如果暂时无法完成,Linux内核返回一个EAGIN,也即需要用户态频繁去尝试。
如下图所示的样子:
③多路复用IO
解决了在一个线程中如何操作才能搞定多个阻塞IO。
它的代码框架实现经历了两个阶段,目前均参在于代码中:
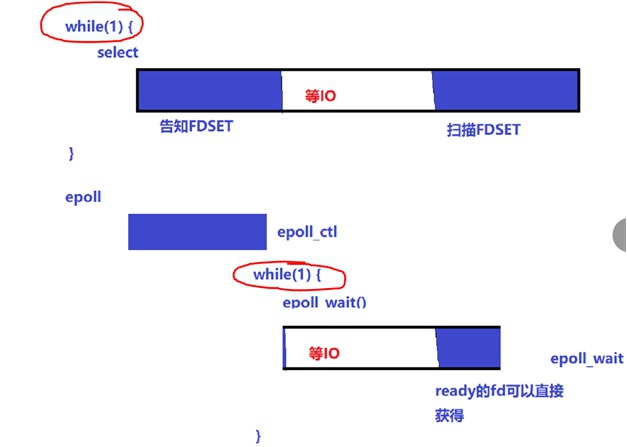
- 早期以select为代表:(对于大量并发网络请求场景,效率依旧非常低)
- 监控:将select需要监控的所有fd加入到一个set中,只要发现有一个fd满足读写事件select就返回。
引入问题:返回后再次select监控时,就需要重新将所有要监控的fd加入set中(“健忘症”),对于大量并发场景这里会有不小开销。
- 扫描:select返回之后,需要for循环去一一检测set中哪些fd被满足了,然后进行处理,
引入问题:循环遍历操作(“后处理”)对于大量并发也会有不小开销。
- 监控:将select需要监控的所有fd加入到一个set中,只要发现有一个fd满足读写事件select就返回。
- 当前以epoll为代表:(增强版的select,解决了以上select的两个问题,分裂出两个API)
//Epoll注册事件:
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
EPOLL_CTL_ADD - 注册新的fd到epfd中
EPOLL_CTL_MOD - 修改已经注册的fd的监听事件
EPOLL_CTL_DEL - 从epfd中删除一个fd
//等待事件触发:
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
Tips:
① 由于epoll将告之监控和等待IO拆分成2个API,相比select前一阶段CPU时间消耗在while(1)循环中变得没有了,“健忘症”被治愈了
② 由于epoll_wait()出参中已经包含了所有满足读写事件的fd,省去了扫描所有fd的时间,这里只需要遍历满足的fd即可,“后处理”时间变短了
因此,对于大量并发场景下epoll消耗的CPU要远低于select的,epoll目前几乎是大规模网络程序设计里面处理并发阻塞读写的代名词
很多网络并发服务的编程框架都是用epoll来做的:
- 一般由一个线程用epoll来监控IO
- 然后再结合多线程模型,将有IO发生的fd的具体工作派发到对应的线程池去处理
- 再把吞吐性能做起来
④SignalIO
SignalIO目前基本很少有人再用了,不过也有一些工具比如perf/strace等还在使用它。
原理是:
- 内核中某个IO已经ready之后,会kill SIGIO信号比如
kill_fasync(&dev->async_queue, SIGIO, POLL_IN) - 应用程序在SIGIO信号上绑定一个hander处理函数,当收到SIGIO信号后进行IO处理
⑤异步IO
纯粹的异步IO在Linux中也是存在的,是指发起一个IO后立即返回完全不需要等待,后台线程会负责IO动作,当在同步等待点上需要同步等待IO完成时再利用某个函数去等待。异步IO基本思想同样也是不让IO去阻塞CPU消耗型的task,将CPU与IO做并行处理,让CPU的归CPU、IO的归IO。

对于在glibc中aio:
一般就是需要发起IO时调用aio_read等IO函数,这些函数会立即返回,然后在IO的同步等待点上调用aio_suspend来等待。
在kernel中的aio版本:
linux提供的一套系统调用,一般是配合硬盘的O_DIRECT形式去访问的。用一系列的系统调用,如io_setup/io_sunmit准备IO,利用io_getevents来在同步等待点等待。
⑥Libevent
现在用户态开发流行基于异步事件的编程模型,libevent也是类似的IO模型,在做大规模网络编程时比较流行的。
所谓“基于事件”,指的是当某一个事件发生时会触发某些动作,比如向某个节点echo一个值之类的,它类似于早期在微软的MFC编程IDE中添加一个button点击button会触发一个事件等等。
在Linux上libevent的底层实现原理是基于epoll的,在其它平台上封装了对应平台的系统调用。
良好的跨平台性,它提供如下一些统一的接口:
//初始化
event_init()
//设置监听处理函数句柄
event_set()
//加入事件
event_add()
//分发事件
event_dispatch()

各种IO模型的对比
总结如下面表格
| 模型 | 特点 |
|---|---|
| 一个连接 <=> 一个进程/线程 | 进程/线程会占用大量系统资源,切换开销大,可扩展性差 |
| 多个连接 <=> 一个进程/线程 select | fd上限+重复初始化+逐个排查所有fd状态(O(n)效率) |
| 多个连接 <=> 一个进程/线程 epoll | epoll_wait返回时只给应用提供了发生状态变化的fd。典型用户:nginx和node.js |
| Libevent跨平台,封装了底层平台系统调用,提供统一的API接口,支持windows-iocp,solaris-/dev/poll,freebsd-kqueue,linux-epoll | 当一个fd的特定事件发生(如可读/可写/出错),libevent会自动调用用户设定的callback来处理该事件 |
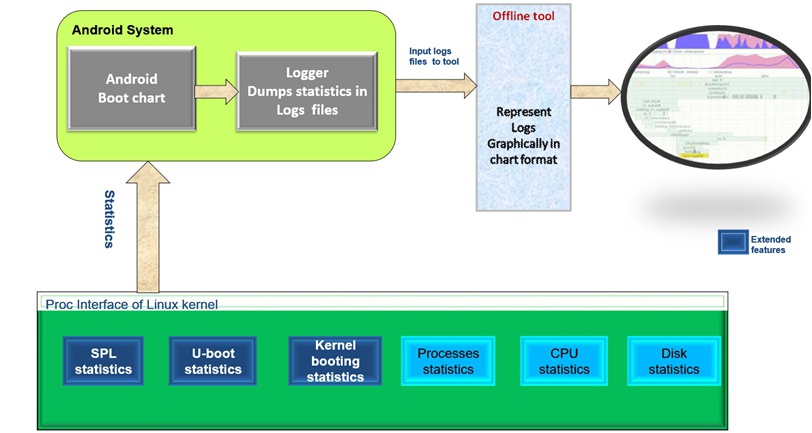
工具集
用于linux与android启动加速,能将CPU和IO消耗阶段转换成图片形式显示、哪一部分用时多少。
它的原理描述起来很简单,就是在代码特定函数中打一些统计点,去记录某一段时间内的各个进程的时间消耗分布情况,抓取log数据并解析成图表形式。
FS架构
文件系统的架构,文件系统与VFS的hook,磁盘上目录与文件的组织,用户态文件系统。
VFS
Linux系统的一个基本设计思想就是“一切皆文件”,它实现这一设计的方法即它的VFS层,通过VFS层把内核“各种类型”的访问转换成对用户态统一的API接口,让用户态看到的就是一切皆文件、一切皆文件操作。
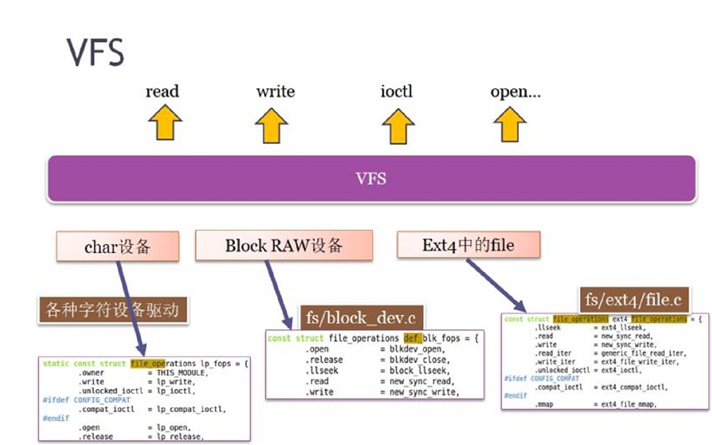
VFS非常类似于CPP中的基类,提供了很多“虚函数”,即面向对象中所谓的“接口”,这个类比是非常形象的,这些接口都需要“实例化”时提供具体实现。
之于VFS,它对上一层提供的“接口”就是read/write/ioctl/open/...这些函数,而实例化,就是对下一层“各种不同操作”所继承的统一struct file_operations结构体进行填充、并且对其内部的函数加以实现。
总之,Linux内核中能够供VFS去hookup(挂接)的,都是file里面的file_operations结构体。
Device File
实现字符设备驱动,就是实现file_operations结构体成员函数。
块设备访问有两种方式,一是直接访问裸分区(如/dev/sda),另一种是访问里面文件系统(如ext4/f2fs)。
当以裸分区形式访问块设备时,块设备文件在fs/block_dev.c中,里面有struct file_operations def_blk_fops的具体实现。
字符设备与块设备区别:
- 字符设备是驱动中自己实现file_operations。
- 块设备是file_operations都被文件系统层(vfs或某具体fs)实现掉了,并不需要在块驱动中再去实现了,虽然已经被抽象但本质上还是存在file_operations这一实现的。
Superblock、Dentry、Inode
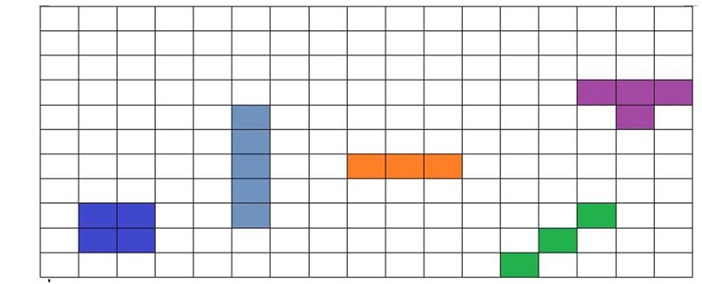
有一个百万格子的网站实践,很类似于磁盘上文件系统的组织,假设每个格子对应磁盘上的一个block块,那么一个file在这些格子上该怎么映射、格子怎么查找、怎么记录空闲格子等等,这些就是文件系统要解决的问题。
① 对于文件本身数据,下面的每种颜色标识一个文件的存储情况,显然一个文件可能占用不止1个格子(多个block块):
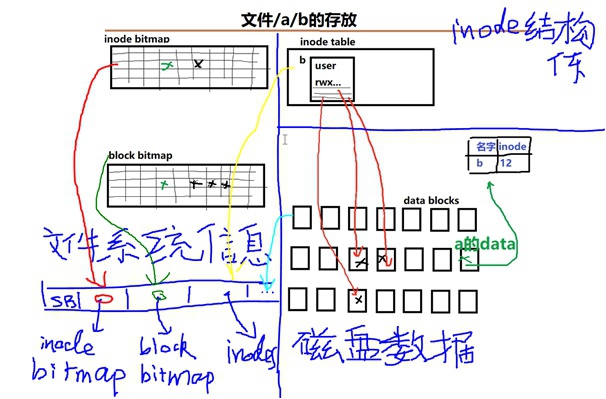
② 在文件系统里面,除了放文件本身数据以外,还需要放文件管理的数据:super block、inode bitmap、block bitmap、inode table等等,他们组织结构如下图:
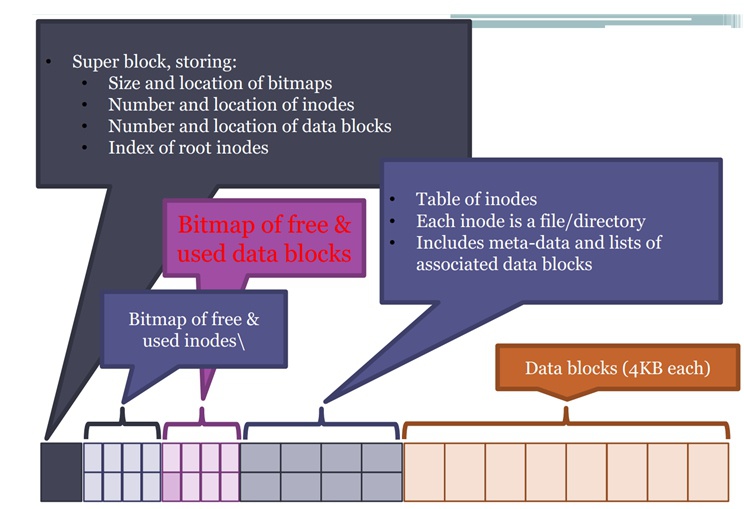
- superblock:文件系统的起始字段,统领所有后面数据结构。
- inode bitmap:假设一个文件系统总共可以支持10万个文件,那么在文件系统中会建立起来一个inode的bitmap,去标记哪些inode是被占用的、哪些inode是未被占用的。
- block bitmap:描述哪些block块(格子)被占用、哪些block块(格子)没有被占用。因为一个inode可能会对应多个block,因此一个文件变大/变小都可能会造成它的变化。
- table of inodes:inode表,这里包含了所有的inode结构体数据,每个inode结构体标识一个文件,这个inode结构体中有各种文件信息,比如文件名字、标记占用block块的第一级inode diagram等等。
文件系统的数据结构
| 数据结构 | 描述 |
|---|---|
| file_system_type | ① 文件系统启动时通过int register_filesystem(struct file_system_type * fs)函数注册; |
| - | ② mount文件系统时通过`.mount->fill_super`去填充: {读硬盘的super_block; 初始化super_block:s_op; 根inode初始化(i_ops/i_fops); 根dentry初始化:sb->s_root} |
| - | ③ umount时s_op.kill_sb()做清理 |
| super_block | 文件系统总体信息 s_op: super_operations 对inode分配/销毁 |
| inode | ① 目录或者实体文件,是"唯一"描述并映射到一个特定文件的数据结构 |
| - | ② i_ops: inode_operations {.create .lookup .mkdir} 生成/查找/创建目录/连接等操作 |
| - | ③ i_fops: file_operations 某种特定类型的文件的operations结构体 |
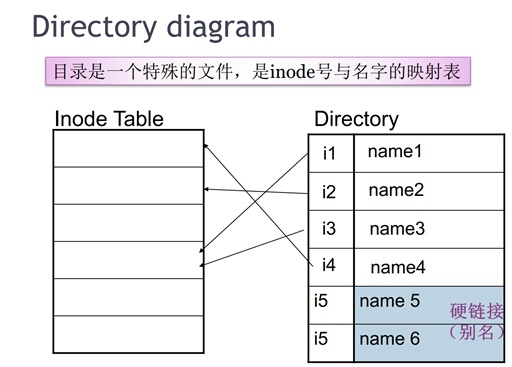
| dentry | ① 目录是一类特殊的文件,它的内容就是一张“名字<=>inode”对照表 |
| - | ② 关于父子关系的描述: dentry->d_inode指向相应inode结构; dentry_operations |
| file | ① 硬盘一个真实文件的一次打开引用,比如一个文件如果被打开100次,那么就有100个file结构产生。(但是注意磁盘文件对应的inode只有一个) |
| - | ② 也即进程级别打开实例 task_struct.file_struct.fd_array[]; |
| - | ③ file.file_operations = inode.i_fops |
inode映射目录或者实体文件,是"唯一"描述并映射到一个特定磁盘文件/目录的数据结构。
inode是文件系统的核心中的核心数据结构,它才是硬盘的真实的存储,其它都是对inode的引用。
代码路径:kernel/include/linux/fs.h
① inode diagram:
在inode结构体中,它是由一些指针组成的,用于记录这个文件在磁盘占用哪些block块,并且对于大文件而言,这个diagram可能需要进行分级(可能因为文件太大而分成多级indirect指向)以满足空间要求。
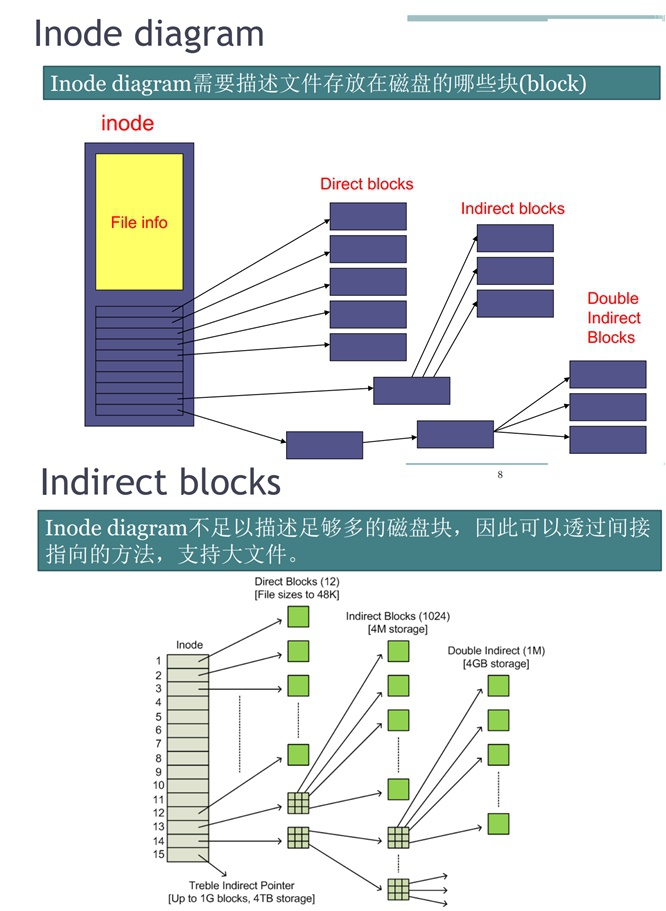
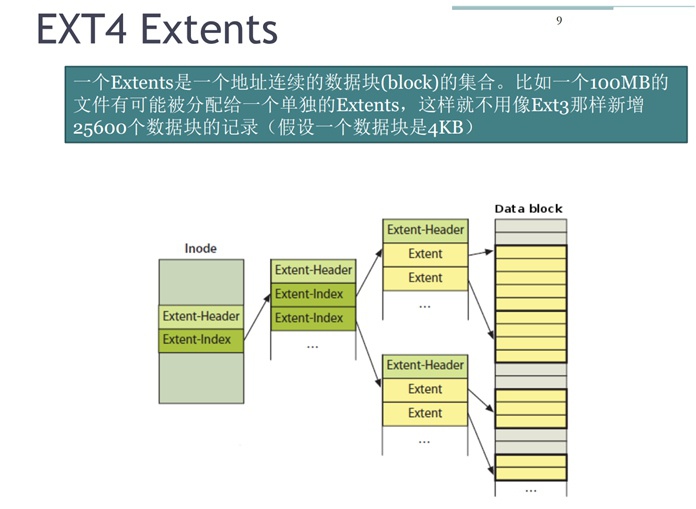
② Ext4对inode diagram的改进:
用Extents数据结构替代之前对block块的记录形式,用以减少间接映射表的层级数量,它的记录方式是将文件在磁盘上某段儿“连续的block”用一个extent记录,这样就免去了一个block记录一次,节省了存储空间、提升了效率。
③ inode cache缓存:
这里的inode cache是各个文件系统在做现实时对“table of inodes”这部分数据的缓存,这部分数据在文章前面有提到,记录了每个inode的数据结构。
在读写文件时inode数据结构的访问会非常频繁,因此为了提高效率用kmem_cache_create创建了专用的slab cache去做了缓存,并且标记该部分slab是可以回收的。

目录在磁盘中是一个“特殊的实体文件”,dentry用于标识一个目录的父子关系和操作,其中dentry->d_inode指向该目录的inode结构。
代码路径:kernel/include/linux/dcache.h
下面这个图是将以上各个部分图形综合在一起,显示的文件如何通过文件系统在磁盘存放的
由根目录"/"的dentry->d_inode
=》找到根目录"/"文件的内容
=》在目录文件中用file name去做字符串匹配
=》找到对应的下级目录inode
=》根据它找到对应下级目录
=》同样重复操作:在该级目录的文件中用file name做字符串匹配
=》找到对应的file文件inode
=》通过file文件的inode找到对应data块,做读/写操作
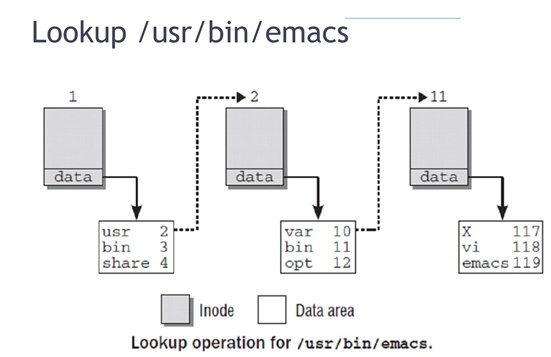
该过程描述:
○ 因为根"/"对应的dentry->d_inode是知道的,所以读取根的inode表,找到对应的inode结构体,读取其中datablock指针这部分,找到磁盘上对应的文件,读取内容,去做字符串匹配"usr",找到它对应inode2;
○ 读取“inode cache缓存inode表,找到inode2的结构体,读取inode2里面的datablock指针部分,找到磁盘上文件,读取内容,去做字符串匹配"bin",找到它对应的inode11;
○ 重复<2>的过程,找到"emacs"文件对应的inode119,查找inode119的datablock指针部分,找到磁盘上文件,读取/写入内容。
文件系统中涉及的slab cache有两级:
- 一级是VFS层次的,保存最通用的信息inode、dentry,不在乎具体的FS实现;
- 二级是具体FS内部的,记录具体FS的"table of inodes"信息;
Symlink与Hardlink
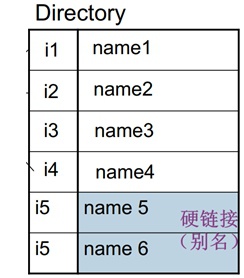
说起symlink和hardlink这里还需要再提及一下目录,文章前面提到过所谓目录是一个“特殊的目录文件”,它里面内容是file<==>inode对应关系表。
对于硬链接而言,它没有单独的inode结构体,只是在目录文件中增加一行,让硬链接文件指向对应的inode。
硬链接:
- 不能跨本地文件系统,它是特定文件系统内部的
- 不能对目录创建硬链接,那么,也不能对目录执行unlink
- 删除文件即删除硬链接,那么,对文件执行unlink相当于对文件执行rm
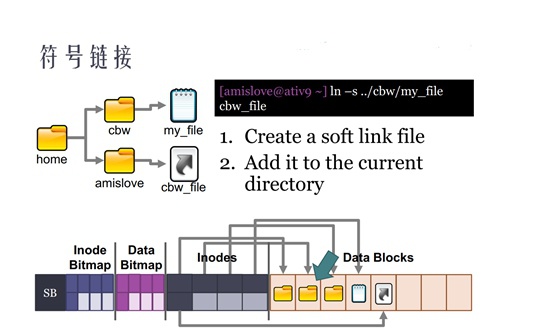
符号链接在linux中是一个真实存在的实体文件,它有单独的inode结构体,只不过符号链接文件“内容”是指向源文件。
符号链接(软链接):
- 针对目录的软链接,用
rm -rf删除时,是不能删除掉源目录中内容的,只是删除了软链接文件自身(rm/unlink) - 针对目录的软链接,用
cd ..时进入的是软链接自身所在的父目录
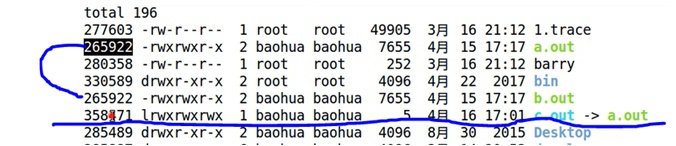
在文件系统中对比Hardlink硬链接和Symlink符号链接
- a.out是源文件;
- b.out是通过
ln -l a.out b.out产生的硬链接; - c.out是通过
ln -s a.out c.out产生的符号链接;
① 创建目录a和文件1、2、3:
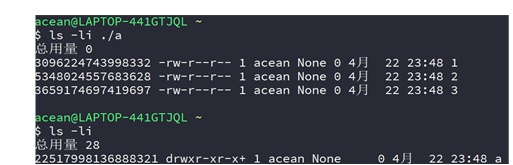
② 创建目录a的软链接b:
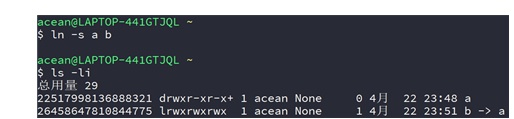
③ 创建软链接b的硬链接c:
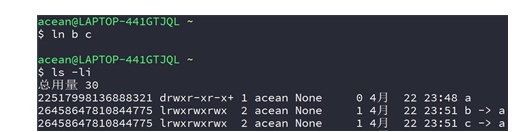
④ unlink目录a的软链接b:
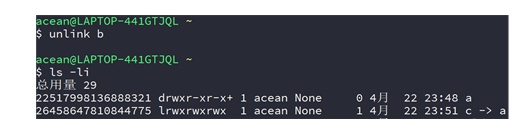
⑤ unlink软链接b的硬链接c:
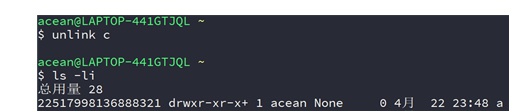
⑥ unlink目录a:

⑦ 创建目录a的硬链接b:

Inode Cache、Dentry Cache、Slab Shrink
Inode Cache简称Icache;
Dentry Cache简称Dcache;
Tips:
这里注意不要与CPU的指令缓存icache、数据缓存dcache混淆!
在VFS层级文件系统中的inode cache和dentry cache是通过slab分配器从特定slab cache中分配的object去cache了“跨所有文件系统通用信息”,而不是具体某种FS文件系统内部的inode、detry等信息。

而占据在VFS生成的这些object上的具体inode结构体中都包含有一个i_private成员,这个成员指向了下一级具体FS文件系统的inode信息,这样VFS与具体FS联系在一起了。
针对以上icache/dcache这些slab cache在linux kernel的kernel/fs/dcache.c实现中写了一个单独的回收接口API:shrink_dache_sb()
比如在我们手动drop cache时执行命令echo X > /proc/sys/vm/drop_caches时,会调用到这个接口,回收时还是根据LRU算法进行,将不活跃的回收掉:

在Linux Kernel中,对于slab cache而言,每一类slab cache是需要单独的回收API的,即需要写单独的shrinker函数。
比如:
- kmalloc创建的kmalloc-64等等slab cache的回收API是:
kmeme_cache_shrink() - kasan这个内存feature中创建的slab cache的回收API是:
kasan_cache_shrink() - fs中创建的icache/dcache这些slab cache的回收API是:
shrink_dache_sb() - ...
而在kernel中有的地方在创建“专用的slab cache”时也会标记reclaim,但是却没有给这些专用slab cache写shrinker函数,就造成了这部分slab object虽然被统计在可回收内存部分,但实际上内存紧张时无法被回收。因此,在写专用slab cache时写shrinker函数这一点是需要特别注意的。
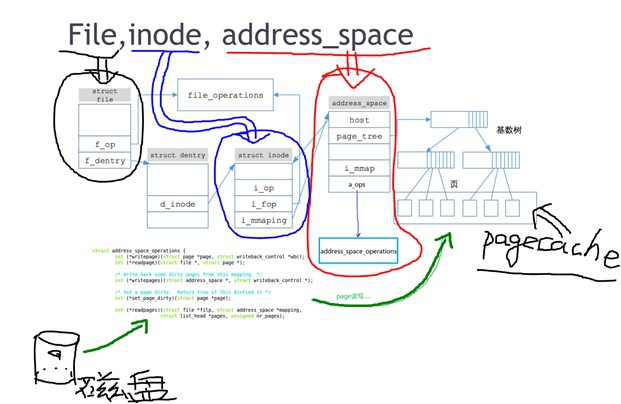
Address Space
每个inode都会通过inode->i_mmaping去对应一个address space,它对应2个重要结构体:
① struct address_space{}结构体,在文件include/linux/fs.h中
- 它是address space总的数据结构,承接了文件系统的inode与磁盘之间的读写转换关系,包含了对这些inode对应的pagecache的管理;(pagecache缓存了磁盘文件内容,即将inode结构体datablock指针指向的那些磁盘block块上内容读入到内存上)
② struct address_space_operations{}结构体,在文件include/linux/fs.h中
- 它是pagecache的操作函数集,包含read/write/directio等,具体到某个FS文件系统的实现函数最终会调用address_space_operations结构体里面的函数,去实现对pagecache的查找和磁盘的读写。
inode->file_operations与inode->address_space->address_space_operations的关系:
inode->file_operations是由具体FS文件系统实现(ext3/ext4)填充的,当打开文件时,它又被填充到task_struct->file->file_operations中,这个file->file_operations又被hookup到VFS中。它的函数集read/write等会调用address_space->address_space_operations里面的函数集来完成相应操作。address_space->address_space_operations它提供了pagecache的操作,它会将磁盘中数据读入pagecache中或者将pagecache数据写回磁盘(发起bio)。

最终文件file的读写是怎么透过file_operations走到文件系统dentry/inode、再走到pagecache、最终到磁盘的?
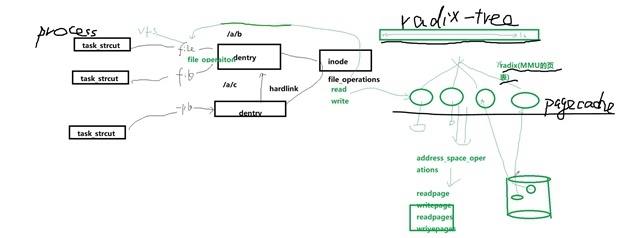
Tips:
并不是所有的fs都像ext3/ext4一样有address space框架这一部分(即上图中右侧绿色部分),有一些简单的fs(比如simplefs)可以是并未接入address space这个框架的,在inode的read/write函数中就直接调用block dev驱动部分操作磁盘了(发起bio)。
用户态文件系统与FUSE
所有的userspace文件系统,在linux kernel看起来都是不存在的,因为在linux kernel注册的文件系统都需要hookup进VFS,而用户态文件系统是在VFS之上的。但是,在内核中有一个模块fuse,对userspace它可以提供API注册接口,对VFS它可以hookup进去。
如下面代码,这里需要实现fuse_operations{}这个结构体成员,同时将它用fuse_main()函数注册进FUSE
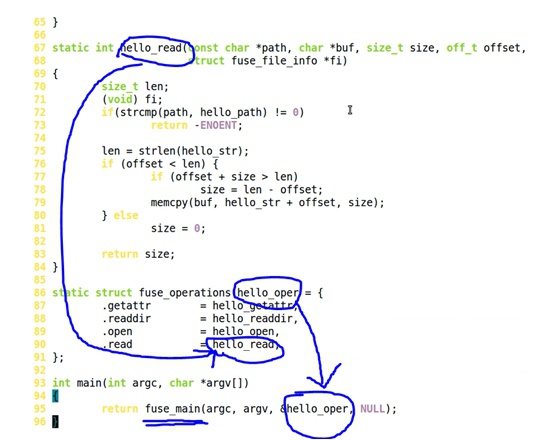
当用户态进程想透过VFS去访问一个userspace文件系统下的文件时,VFS先通过fuse转化成消息传递给userspace,然后userspace操作完毕之后再将消息传递给fuse,然后fuse再传递给VFS,VFS再反馈给用户态进程。
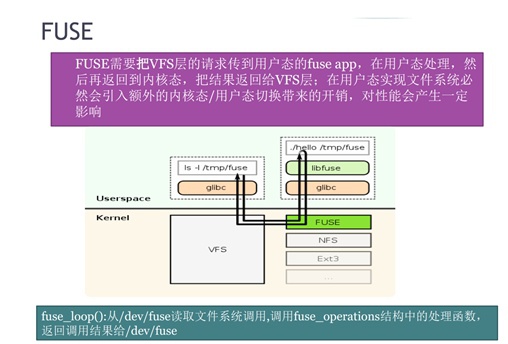
这个过程非常繁琐,涉及到内存频繁在用户态和内核态之间互拷、消息在用户态和内核态之间互传,因此效率肯定是不高的,但是实现成本很低,因此对于性能要求不高的场景会有应用优势。而且,通过fuse可以快速实现文件系统原型,因为是用户态的东西调试起来也很方便。
Tips:
zfs是写时拷贝(copy-on-write)文件系统的鼻祖,后来的btrfs等都是学习它的。
在Linux中有一个通过fuse实现的zfs文件系统,但是效率很低,相比其它内核态文件系统,它基本没有使用价值。
FS工程实践
预备知识:数据库里的transaction(事物)有什么特性?
- 原子性(Atomicity):事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行。
- 一致性(Consistency):事务应确保数据库的状态从一个一致状态转变为另一个一致状态。
- 持久性(Durability):一个事务一旦提交,他对数据库的修改应该永久保存在数据库中。
ext2/3/4的layout
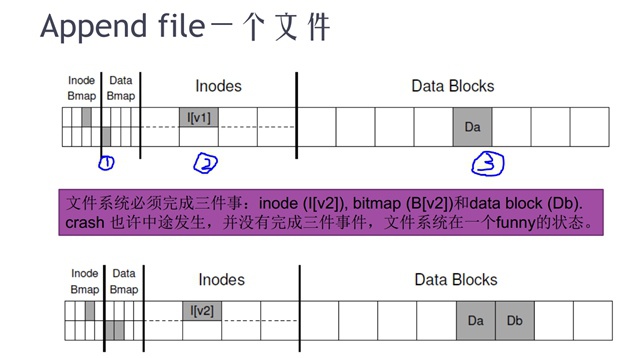
Linux中修改一个文件涉及到好几个结构体:inode bitmap、block bitmap、dentry inode、file inode、data block等,这就是fs的layout,即修改一个文件并不是一个原子性的操作。
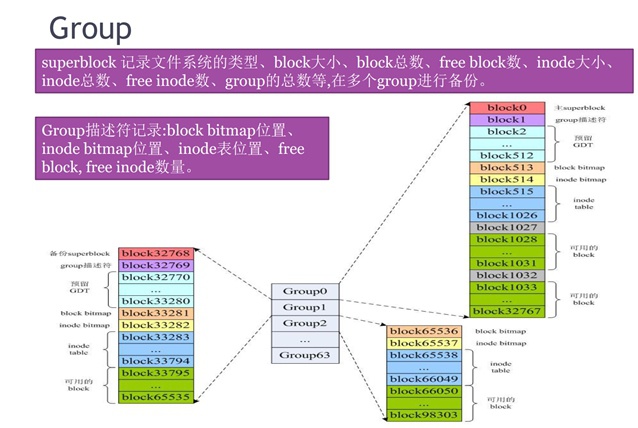
磁盘在被具体fs组织起来的时候,是以group为单位进行管理的,这样做的好处是:能尽量将同一个目录下的file摆放在同一个group中,这样会避免在连续访问同一目录下的file时在磁盘上跳转的很远,能加速查找的过程。
① 除了第一个group中的主superblock以外,其它会有备份的superblock曾强整个fs的鲁棒性,相应地也增加访问时间和浪费存储空间。
② 每个group中都有自己的group描述符,来记录该group中的inode bitmap、block bitmap、inode表等等位置信息。
fs的一致性:append一个文件的例子
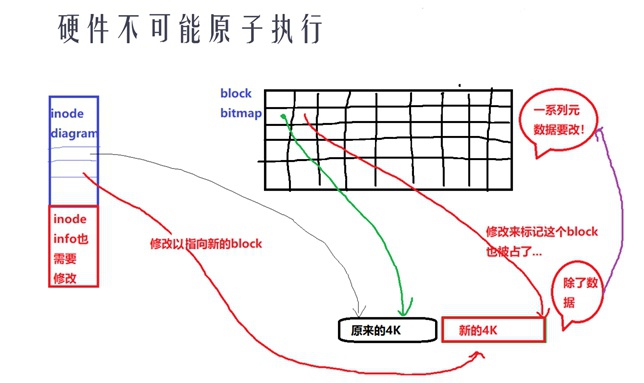
掉电与fs的一致性
fs的这种非原子性操作造成结果是:当有掉电等场景时,就可能造成文件的丢失、损坏等等。
比如:
① 假设先修改了元数据:如果元数据都被修改完了,但是datablock的数据只写了一半,这时掉电了,那么造成的结果是一上电后打开该文件,可能就偷到了之前在磁盘上这个datablock保存的文件内容了;(安全性问题)
② 假设先修改了datablock:如果数据已经写完了,但是元数据还没有写完,会造成元数据之间不一致,文件系统状态错误了;(文件损坏、截断、文件系统损坏)
② dump一下文件系统信息:dumpe2fs image,查看block bitmap和inode bitmap的位置
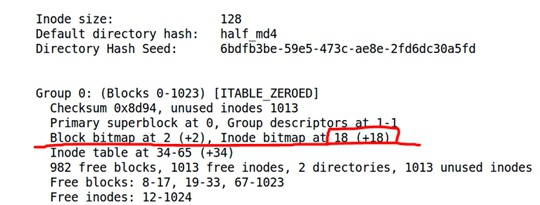
③ 查看一下inode bitmap对应部分内容:dd if=image bs=4096 skip=18 | hexdump -C -n 32,skip是跳过的block(每个4096大小),这里注意文件中是小端模式保存数据,低byte在第地址高byte在搞地址,因此组成一个64bit/32bit的bitmap时需要高低byte颠倒一下顺序。发现inode bitmap记录是0x07ff,根据1bit对应一block,说明前11个bloc都是被占用的,新的file将从第12个block开始。

④ 将image mount到本地:mount -o loop image aaa,进入aaa中:cd aaa,创建文件nihao:touch nihao,查看nihao这个文件的inode号:ls -i nihao发现是12,比对一下之前inode bitmap中查看到的是一致的。
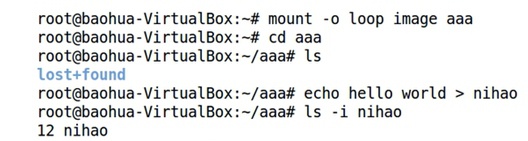
⑤ umount掉:umount aaa,再次dump一下inode表:dd if=image bs=4096 skip=18 | hexdump -C -n 32,可以发现里面标记有改变,标记了这个nihao文件占用了哪几个datablock了

⑥ 用vim -b image以二进制模式打开这个image,在vim中切换编辑模式:%!xxd -g 1修改inode bitmap记录,切回二进制模式:%!xxd -r然后保存退出
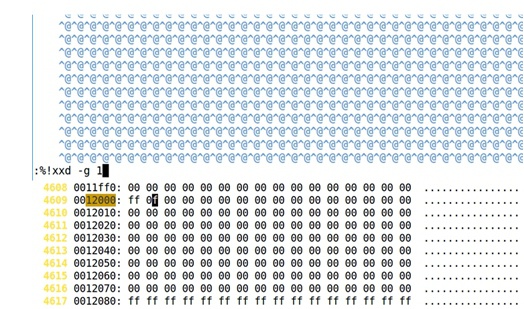

⑧ 此时文件系统已经存在不一致的情况了,尝试用fsck.ext4这个工具去修复fsck.ext4 image,发现它并没有检测出来fs不一致的情况。它并没有删除fs中记录的nihao这个文件的其余部分、或者也没有补齐inode bitmap中记录的比特位。(当然,这里可以用fsck.ext4 image -f命令强制修复还是可以的)

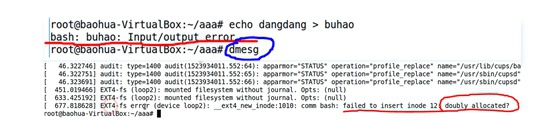
⑨ 再次将该文件mount到本地mount -o loop image aaa,发现inhao文件依旧存在,查看inode号ls -i nihao依旧是12。但问题是:这时inode bitmap中的第12bit早就已经却已经被我们置为0了,虽然fs不一致却依然可以工作。。。

⑩ 在该目录下重新创建一个文件echo dddd > buhao,这时发现文件系统报了I/O错误,这是因为inode bitmap标记12号inode是空的,但是其它对应12号inode的信息却都存在。用dmesg查看kernel log发现ext4文件系统报错:inode被二次分配。
Tips:
从以上例子可以看出,文件系统不一致时,文件系统读访问也可能是正常的,但是写入一个文件时就会报莫名其妙的错误,后续再无法写入了。
fsck
基于以上描述,突然掉电对于fs的一致性损害是非常大的,很可能造成fs不能使用了、重要数据丢失了等等。
在Linux Kernel早期,当出现异常掉电时,下次开机会首先自动运行一个fsck程序,该程序对fs进行检查,并尝试修复fs不一致的情况,它会询问用户意见如何修复等等。

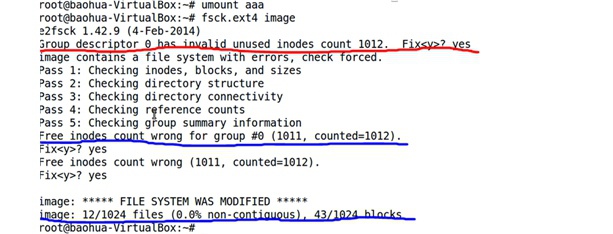
Tips:
之前直接修改完时,用fsck是没有发现错误的,但是这里在建立新文件报错后,再次用fsck是可以检查到错误的
另外,可以使用fsck.ext4 -f参数来强制修复,也是可以修复之前错误的
这里需要再次提及的是,无论软件技术有多么牛逼,也是无法保证掉电不丢数据的,只有硬件上UPS电源、大电容才能彻底确保不丢数据。而软件只能提供fs的一致性保护(恢复/修复)
fs的日志系统
fsck是可以修复fs不一致问题,但也有自身缺陷:fsck检查和修复fs的速度是非常慢的。因此,目前文件系统的一致性保护,都是使用fs的日志系统。
fs的日志系统借用了数据库的transaction的概念,数据库里的transaction(事物)的特性:
- 原子性(Atomicity):事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行。
- 一致性(Consistency):事务应确保数据库的状态从一个一致状态转变为另一个一致状态。
- 持久性(Durability):一个事务一旦提交,他对数据库的修改应该永久保存在数据库中。
① 首先去写一个日志区,然后将日志commit了,表示日志已经写完了;
② 真正去修改fs中内容,写完后checkpoint该日志,表示fs中内容刚已经写完了该日志没有用处了;
③ 最后日志系统将该日志free掉;

以上fs操作中每个环节都可能发生突然掉电,因此日志对于fs一致性保护的操作是:
① 日志未commit:日志损坏,下次上电直接放弃该日志,当作修改fs动作从未发生过
② 日志已commit未checkpoint:下次上电时回放日志,写入fs中即可

从日志操作的流程上看出,以上操作的开销是很大的,意味着每次通过fs写磁盘都会做2次写操作(元数据+data数据),这对IO性能是一个极大的挑战。
因为对于写fs时显然datablock数据块是更大的部分,因此是否可以只将元数据部分做日志、即只确保fs的一致性,而不是去保证元数据与datablock数据的一致性??即:掉电后fs通过日志还是可以正常工作的,而datablock数据可能错了。在这种情况下,fs的元数据和data数据可能就对不上了,但是也只能如此来确保fs的读写性能了。如果只做元数据的一致性的话,datablock部分可以单独来搞了。


如上图,
① 对于只做元数据日志(metadata)时,有两种情况:data=writeback和data=ordered
- data=ordered:是指在写元数据之前先写datablock数据,这样能避免元数据写完了但是datablock没有写完情况,但效率会稍差一些
- data=writeback:是指可以同步写元数据和datablock数据,不需要等待datablock数据写完再对元数据做日志,效率更高一些
② 如果元数据和datablock数据全做日志:data=journal
- data=journal:是指datablock数据也需要做日志,但是效率最低,写入速度会慢1倍(因为写2份)
其实,日志无非有两个特性:一是备份、二是锁
ext4 mount选项
TODO...
工具集:fs的debug和dump
fs相关工具集,这些debug工具和方法对于快速查看和定位问题还是很重要的
查看硬盘分区情况:
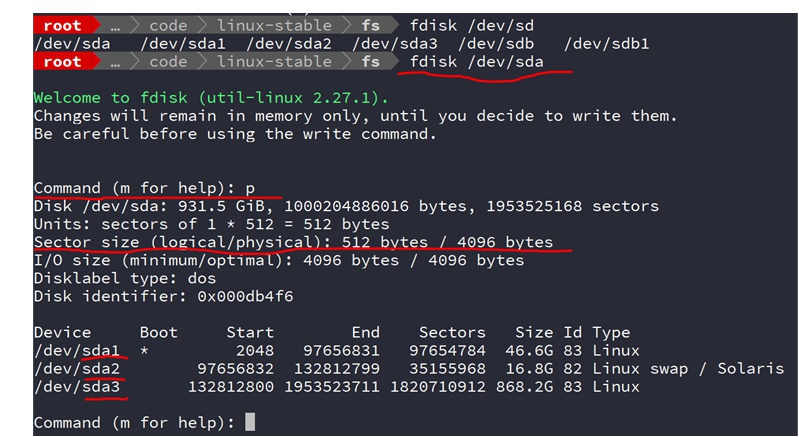
格式化文件系统,例如前面制作一个block=4KB大小的文件:mkfs.ext4 -b 4096 image
查看block bitmap和inode bitmap的位置,例如前面查看image的inode等信息:dumpe2fs image
通过*直接读取block块*内容来查看其上存贮的原始数据(打印出来的内容是存在block块号1015373上的数据):blkcat /dev/sda1 1015373
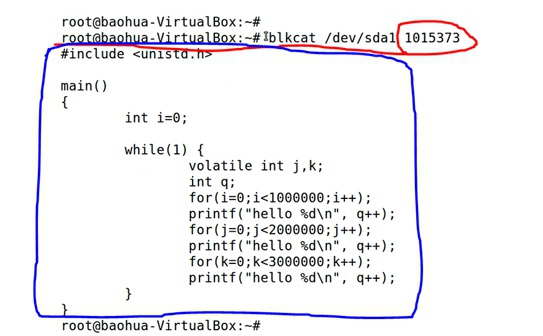
通过*直接读取sector(扇区)*来查看其上存贮的原始数据,一个block是4KB大小,每个sector是512bytes,这样一个block上有8个sector,所以计算一个block号对应的sector时用(block number * 8)。通dd到文件中的结果见该文件末尾还是一堆@@@符号、还并没有占满整个sector:
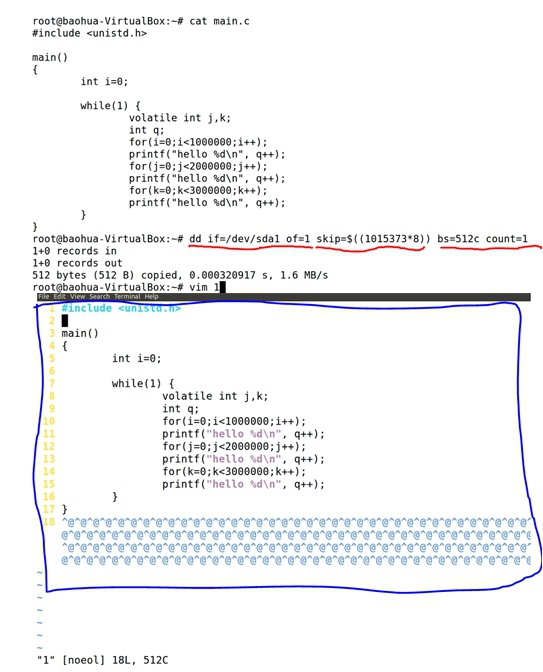
注意这里指的是调试文件系统的debugfs工具,而不是指的Linux Kernel的调试文件系统debugfs。
- 开启root用户模式
sudo bash

- 用debugfs查看文件状态
debugfs -R 'stat /home/baohua/main.c' /dev/sda1
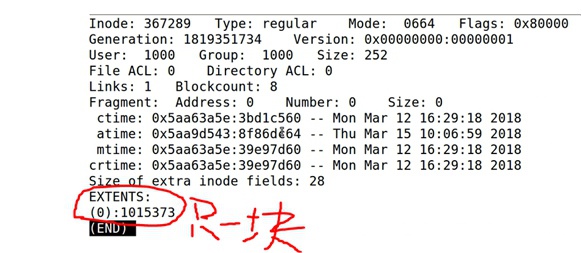
- 用debugfs通过block号查看inode号
debugfs -R 'icheck 1015373' /dev/sda1

- 用debugfs通过inode号查看filename路径
debugfs -R 'ncheck 367289' /dev/sda1

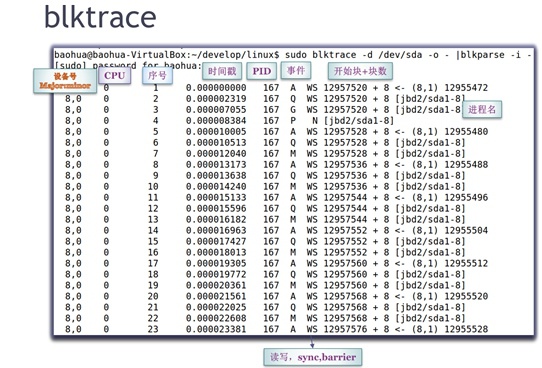
这个工具是专门用于跟踪block io的整个生命周期的,能观测到bio层面的plug queue、elevator queue、dispatch queue的三进三出,如果进行bio层面的分析该工具几乎是必须的;它的原理是在内核中的一些关键函数点上增加了一些记录信息,然后抓下来这些记录并且解析。
这个工具执行后的效果如下面显示,包含了设备号、执行core、序号、时间戳、pid、事件、读写/sync/barrier、开始块/块数、进程名等等。执行的例子如下: blktrace -d /dev/sda1 -o - | blkparse -i - > 1.trace
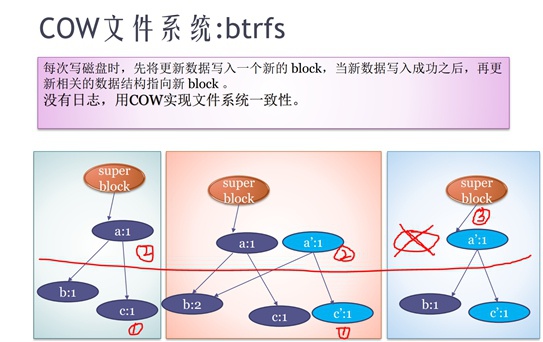
Copy-On-Write文件系统:btrfs
btrfs是一种通过“读-拷贝-更新”来完成fs修改的文件系统,这个文件系统是没有日志的(也不需要日志),它是通过copy-on-write来实现fs一致性的。
所谓cow,即当写入fs的操作时,先去读取需要写入的block并对它拷贝一个副本,然后更新副本中的内容,最后再把它上一级节点做拷贝更新,如此一级一级向上修改,一直到修改superblock节点指向(这个修改是原子的),完成整个树状结构修改:
- 在修改superblock指向前任意时间断电,都不会造成fs一致性问题,因为superblock一直是指向老树
- 在修改superblock指向后任意时间断电,也不会造成fs一致性问题,因为superblock已经修改指向新树
- 而修改superblock指向是一条指令,属于原子操作,不会有断电问题
btrfs的transaction完全是靠树是否更新完来决定的,对btrfs的cow流程更加详细的描述如下:

因此,这个文件系统以cow替代日志,一是效率很高,二是很适合做快照这种场景(只新建一个快照的root即可);

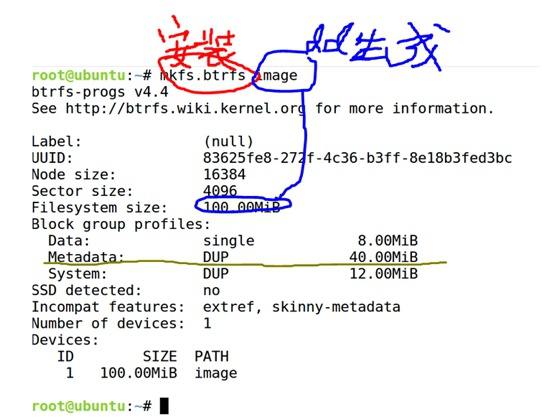
下面是一个展示btrfs文件系统的一些简单操作的示例,创建、挂载、快照、子卷等操作:
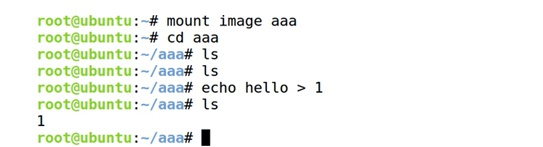
② 把image做mount到aaa目录,cd进去,创建文件1
③ 在这个btrfs文件系统下创建一个snapshot快照btrfs subvolume snapshot . snapshot1,snapshot是一个特殊的子卷,它有一个指向原来文件系统的指针
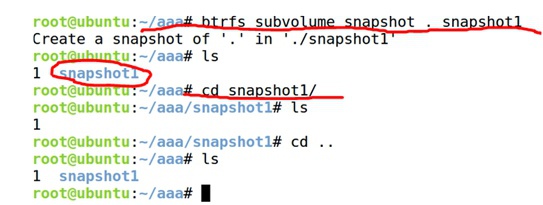
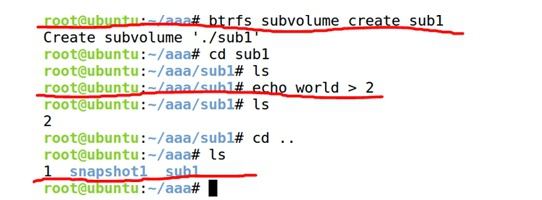
④ 在这个btrfs文件系统下创建一个子卷btrfs subvolume create sub1,在子卷中创建一个文件2

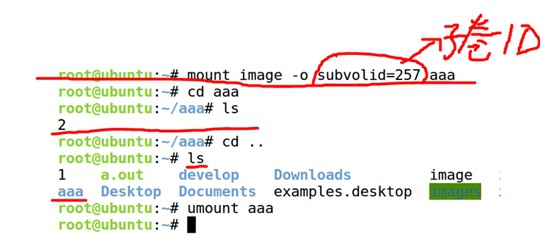
⑦ 测试快照snapshot的cow功能,在生成snapshot之后又创建了一个文件added,然后单独mount snapshot快照这个子volume,发现里面并没有added这个文件,说明在创建新的added文件时执行了cow,这时snapshot与.已经指向不同的fs树了
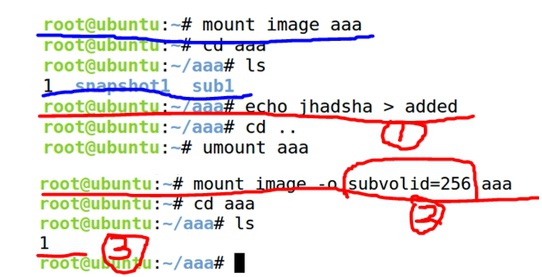
Tips:
这里引申出一个有cow的fs的一个功能:当升级fs时,可以先做快照,然后再升级原fs,如果升级失败可以回滚使用快照即可,不会影响到分区加载、或者系统启动
Block IO与IO Scheduler
BIO与IO调度是介于vfs/fs与磁盘之间部分,通过pagecache、电梯算法queue等实现了对磁盘的统一读写,这里也是IO的性能瓶颈之一。
一个块IO的一生:从pagecache到bio到request
应用程序对于磁盘的访问流程,是能够以pagecache为界分成两个较为明显的层次的:
- 第一阶段:从file到pagecache,这里是文件系统部分
- 第二阶段:从pagecache到bio到request到磁盘,这里是块设备驱动部分
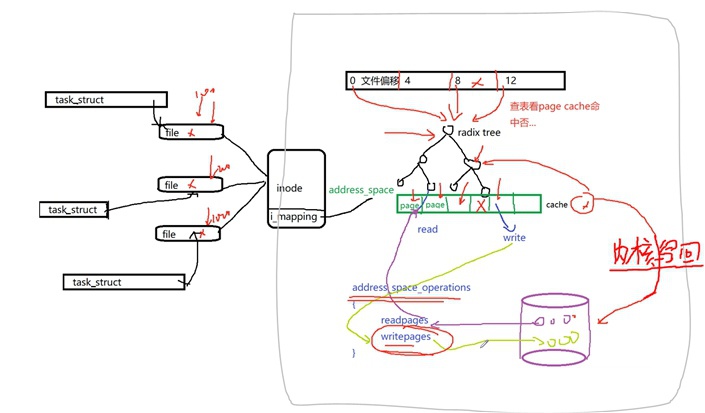
① 左半个部分:是第一阶段“文件系统部分”从file到address_space_operations的图示,之前章节已经介绍过了
- fs的read/write函数会首先看pagecache是否命中,命中则读写pagecache后返回;
- 如果未命中,下一步,调用address_space的readpages/writepages函数,去“透过”pagecache中的page页读写磁盘的block;
② 右半个部分:灰色框体内是address_space的软件架构,左侧通过inode->i_mmaping指针嵌入inode结构体中与fs交互,右边依靠块驱动部分与磁盘交互
- address_space,顾名思义“地址空间”,它指的是“file文件==(通过)==>RadixTree==(映射到)==>pagecache的page页”组织结构
- 磁盘通常情况以4KB为一个block进行格式化和读写,因此RadixTree在组织时会将file的偏移(0、4、8、12、...)与pagecache中每个page页(4KB)建立一一映射关系
- 当读写file文件内容时,先通过偏移在RadixTree中查找是否有对应的pagecache页,有则读写后直接返回
- 如果没有,则调用address_space_operations中的readpages/writepages函数,先在内存中申请一个page页,然后修改RadixTree将该page挂入pagecache中,然后在从磁盘读入内容到page或直接写入page
- 块驱动部分,从最广义上来讲,包含bio、io调度、block驱动等各层级
Tips:
这里有几个概念需要澄清一下,它们的大小关并系不固定
○ page - 内存管理的最小数据单元,Linux内核通常4KB
○ block - 文件系统管理的最小数据单元,通常按照page页大小来格式化成4KB读写性能好,另外,因为一次会读写磁盘的一个block,当文件小时block越大会越浪费磁盘空间
○ sector - 硬件读写磁盘的最小数据单元,跟硬件有关
① 对于pagecache而言,在做内存统计时是区分buffers和cached,它们都是通过RadixTree来组织的
- buffers是指以“裸分区为背景”(直接读写)的磁盘读写,比如/dev/sda1
- cached是指以“fs为背景”(透过fs读写)的磁盘读写,比如/mnt/a/b.txt
② address_space中标记的pagecache究竟是buffers?还是cached?这是由指向的是address_space这个结构体的指针inode->i_mmaping决定的。
如下显示,在统计buffers占用内存时,函数nr_blockdev_pages()会遍历所有“原始块设备”,把它们里面inode->i_mmaping->nrpages全加在一起算总值。注意:这里遍历的直接是设备的inode!

而所有pagecache加在一起,刨除以上buffers的值就是cached部分,cached部分的inode->i_mmaping并不在原始设备节点inode中,而在fs文件系统里面的inode中。
参数:O_DIRECT和O_SYNC
Linux有两种办法让读写磁盘时不经过pagecache的,这两个参数是O_DIRECT、O_SYNC。
这两个的区别是:
- O_DIRECT:应用程序直接写入到磁盘中(类似于将内存配置成不带cpu cache的,注意这里仅仅是“类似”来做个类比而已)
- O_SYNC:首先写入pagecache然后接着马上再写入磁盘。(类似于cpu cache的write through写穿)
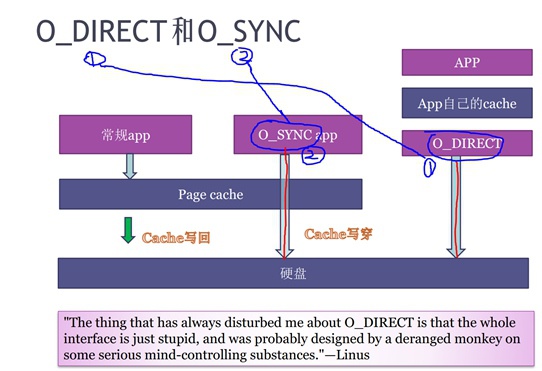
一般情况下,O_DIRECT参数是基本上没有人使用,因为会引入2个问题:
- ① 一旦某一个应用使用O_DIRECT,那么需要该应用程序自行做磁盘cache的管理,因此只有某些很特殊业务逻辑的应用才可能会使用这个。比如某些做数据库的公司可能会这样使用。
- ② 一旦某一个应用使用O_DIRECT,那么其它应用程序如果还是非O_DIRECT就会造成pagecache与磁盘数据的不一致,这种情况下coding时需要非常小心仔细地确认涉及到的pagecache是否做了同步,需要内核去做pagecache的flush和invalid。
基于以上,因此Linux内核一般不建议用O_DIRECT,而如果非要O_DIRECT就所有磁盘访问都采用O_DIRECT,这样会比较安全。
Block IO
BIO的作用:
处理磁盘的哪些block(fs单位)最终需要被读到哪些page上(memory单位),而且进一步,最好是磁盘的哪些blocks最终读到哪些pages。
它是一个最原始的从block到page之间的对应关系,如下图所示,如果通过inode表查询到file它的datablock在磁盘上不是连续的一段,那么,每个独立的datablock就被address_space_operations组织成一个bio:
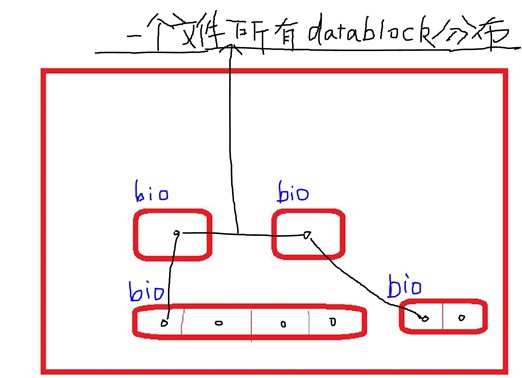
Tips:
当fs被格式化成的(block大小 < page大小)的时候,这时候可能一个page就对应着几个bio(也即对应几个不连续的datablock)
这时会有大量的bio产生,会对性能产生影响。
因此,当格式化成的block较大就会造成空间浪费,当格式化成的block较小就会造成性能降低。这里也恰恰体现了“时间空间互换”的编程思维。
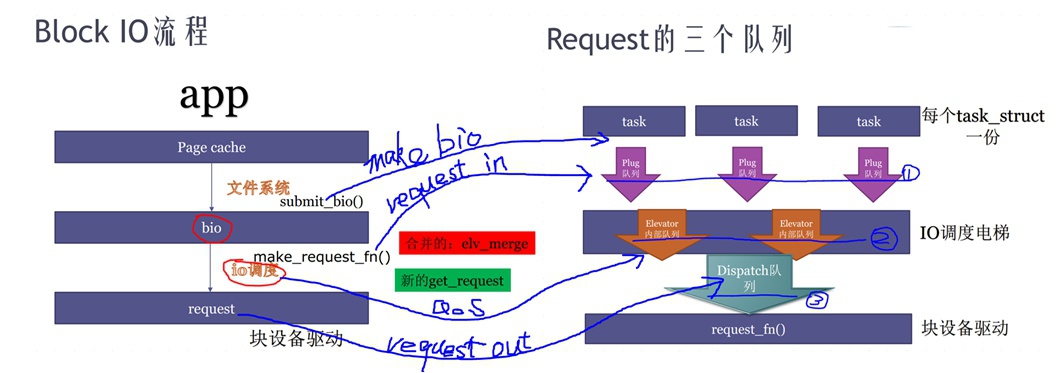
BIO处理的流程:(plug queue、elevator queue、dispatch queue队列三进三出)
<1> “生成”:address_space软件框架部分将从fs的inode表中读出的所有datablock打包生成bio;
<2> “蓄水”:bio会首先被发送到本TASK的“闸门”——plug队列,在插入plug queue之前需要将每个bio转换成request(转换方法是先找bio是否能够match到某一个request,如果不能的话就创建一个新的request,不同的bio可能会被组合到同一个request内,因为request会被对应到磁盘连续空间上);
<3> “防水”:当本TASK的plug队列积蓄到一定程度或者task认为足够了,就“开闸”放水,将plug queue内的所有request都发到“IO电梯调度队列”中,这样汇总起来,所有TASK的request最终都进入到IO电梯调度queue中;
<4> “QoS”:IO电梯调度queue将根据不同的电梯调度算法(Deadline,cfq等等,这里算法更新很快)不同策略,将这些request进行排序,然后将排好序的request放入dispatch队列;
<5> “收发”:这个dispatch queue被块设备驱动使用,块设备驱动将会从dispatch queue中取出一些request,将这些request发送给磁盘host controller


从ftrace的执行结果上看,这里不单单是有函数调用关系图,还有每个函数的执行时间,因此可以用于在验证性能时抓热点函数。
IO电梯调度算法
IO电梯调度算法有很多种,目前比较流行的调度算法有NOOP、Deadline、CFQ三个。
虽然算法不同但是中心目的都是做QoS的(优先级、流量控制、资源预留等等)。比如:
- NOOP只是合并技术,并不排序,比较适合固态硬盘(随机访问无磁头),并不适合磁盘
- CFQ是完全公平调度,指定进行调度实时星、优先级、nice值。类似进程调度CFQ。
- Deadline既要优先级排序又要优先保证读、保证写不会饿死;

修改某个硬盘的IO调度算法:

IO性能调试与调试工具集
操作级别分析工具,跟踪每个IO从上到下流程
见上面工具集:“⑦ blktrace”
函数级别分析工具,分析函数调用关系和函数执行时间。
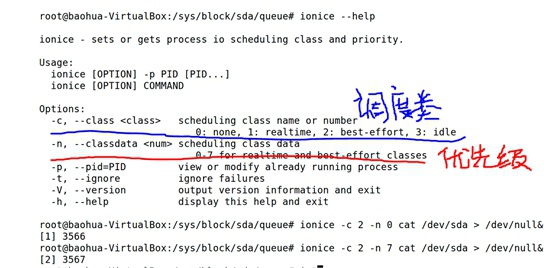
TASK的IO调度优先级不一样,会影响到TASK访问磁盘的速率。如下iotop查看的3546优先级=0,3547优先级=7,访问磁盘速率还是蛮大的。
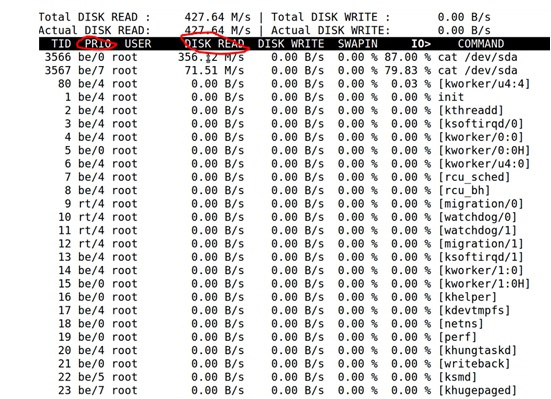

正如进程调度、内存管理里面的cgroup一样,在IO部分也可以通过区分不同的cgroup来控制IO资源的使用(基于权重的优先级、绝对的优先级、调度类等等等等)。

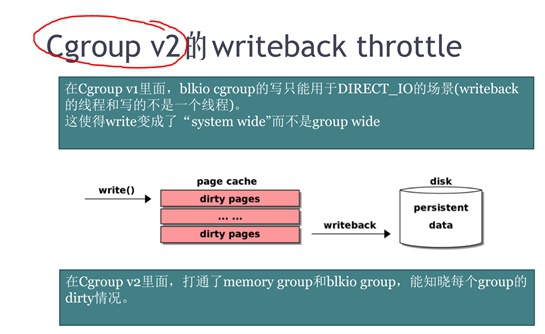
在cgroup v2版本中,在memory管理子系统中去监控了TASK写的dirtypage,然后控制dirtypage被写回的速率来控制IO写回速率。
Tips:
在新版本Linux Kernel中Cgroup V1和V2两个版本是同时存在的,需要选择一个生效!切记!
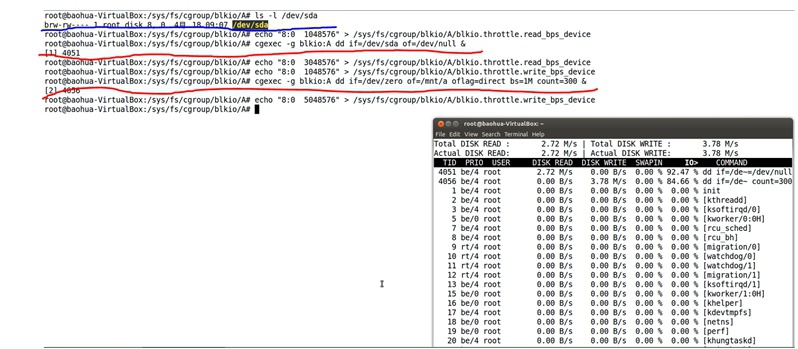
读写限速的例子:
参考文档
真诚求问还有没有宋老师上这个课的原视频,非常想学习一下
@975935259 如果有的话烦请作者发我邮箱一份可以吗?975935259@qq.com
@975935259 同问
@975935259 这个真的没有了,时间太长了,而且当时也是微信语音形式,没有视频的。
@ace 那语音文件有吗
同问,可以有偿,内容很好。