【概述】-Linux内核调试
内核调试其实是一个非常大的议题,从log、defcofig、tools、features等等方方面面是非常复杂的,不可能用一篇文章就完全概括了,这里我们只说一下工程实践中,最常用的一些要点。
从Bootargs设置说起
对于SOC厂商的工程师,一般有两种选择去调试Linux内核:
- 一是Trace32/DS-5这种仿真器 - 一般能够定位和解决硬件故障,总线hang死这类软件手段跟不进去的问题
- 一是Printk - 开启早期printk打印,通常90%以上的问题都是能用printk解决的
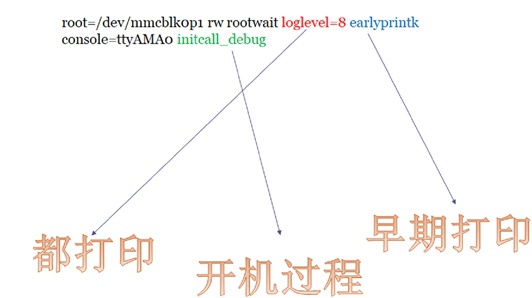
参数说明:
- earlyprintk和earlyconsole:
这里SOC厂商工程师需要从Linux Kernel启动第一步就去打印信息,因此需要在内核tty驱动暂时不能工程情况下,直接将数据写到uart的TX寄存器中。代码路径
/kernel/arch/arm/include/debug/*.S - loglevel=8:
Linux Kernel有0~7个一共8个打印级别(err、warning、info等等),这里设置成8指的是所有信息均打印到uart口,不做log级别过滤,如果做过滤的话可能会信息不足。
- initcall_debug:
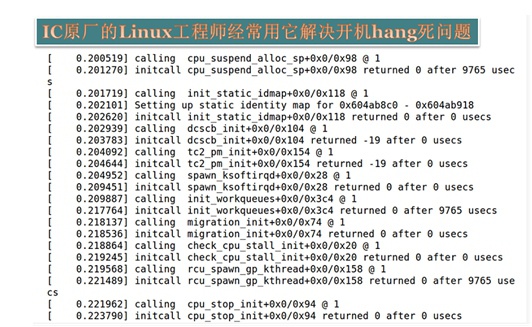
Linux启动过程中有上百个初始化函数,它们会根据调用的初始化入口函数不一致(如module_init()/platform_init()等)而分成7个level级别,每个级别会被放到不同的init.section段中,这样在开机初始化时,从第一个section段开始,用一个循环调用这些初始化函数。所以,当在bootargs中设置这个参数时,Linux会自动将每个init函数的调用打印出来,如下图所示:
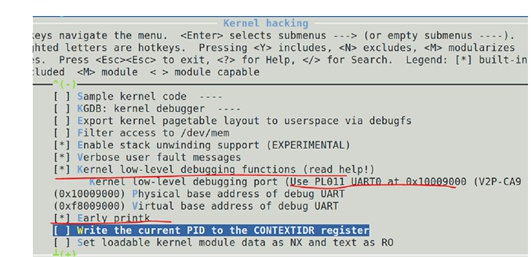
在defconfig中进行low-level的debug选项配置,选择DEBUG_LL和port:
在android系统(AOSP)中(无LCD显示)的底层linux kernel常用的bootargs参数:
console=ttyS0,115200 earlyprintk=uart8250-32bit,0x28001000 root=/dev/ram0 init=/init rootwait rw video=vfb androidboot.hardware=ranchu androidboot.selinux=permissive no_console_suspend initcall_debug解析:
- console用ttyS0,波特率115200
- earlyprintk用uart8250-32bit,地址0x28001000
- rootfs位置/dev/ram0
- init可执行文件是/init
- rootwait让内核在挂载文件系统前,等待root文件设备的初始化工作完成,否则可能会出现mount rootfs failed
- video使用vfb虚拟LCD
- androidboot.hardware硬件名称ranchu
- androidboot.selinux置为permissive只做文件权限检查,但不阻止访问
- no_console_suspend串口console不睡眠
- initcall_debug打印进出init0~7级别的每个函数的名字,一进、一出
Printk及其变体
printk
printk是可以直接在任何上下文环境中使用的,包括中断、软中断、spinlock等等,因为它原理是:将log信息直接打印到kernel的一个固定circle buffer中。而这个buffer是开机就已经分配好的,从kernel管理的线性内存区间分配出来的内存,不会产生缺页异常也就不会睡眠,buffer大小可以在defconfig中调整。
printk是有0~7打印级别的,数字越小优先级越高(0是最高优先级的),有err、warning、info等等等等,注意“这些打印级别仅仅是针对输出设备而言的”,不在串口或者console打印并不代表不进入内核的logbuffer,它里面还是有这些打印信息的。

当cat这个sysfs文件系统下节点时,会出现4个数字,它们值的大概范围都是0~7,解析如下:
- 第一个参数4:表示控制台或者串口当前的Priority,只有Priority<4的消息才会被输出到控制台或者串口
- 第二个参数4:表示printk()函数当前默认的Priority
- 第三个参数1:表示控制台或者串口当前“可以接受的”最高Priority
- 第四个参数7:表示控制台或者串口默认的Priority
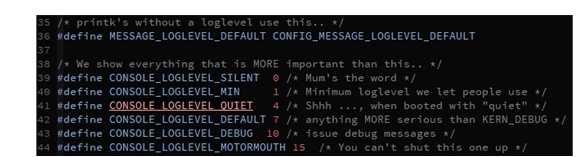
printk的性能开销很大,尤其是串口打印,当printk打印非常多时会导致系统很慢、可能还会丢失log,所以通常会选择在bootargs中添加字段“quiet”来讲console打印机别控制在0~4范围内。
一般情况下,我们在Kernel调试中不直接调用printk,而是使用它的两个变体(通过#define宏定义好的):dev_XXX和pr_XXX
GCC等编译器内置了一些参数可以共printk及其变体来使用作为fmt格式打印的:
- __FUNCTION__ / __func__:所在函数名字
- __LINE__:所在行号
- __FILE__:所在文件名字
- __DATE__:当前日期
- __TIME__:当前时间
dev_XXX
dev_XXX是在device driver中常用的printk变体:
- 它会用device结构体作为第一个参数,用作打印前缀,这样就容易知道是哪个模块驱动出现问题了
- 这里XXX代表的是打印级别0~7,比如dev_err/dev_warn/dev_info...
如下图所示:

pr_XXX
pr_XXX是在device driver以外的代码中(因为无device结构体可用)常用的printk变体:
- 可以用pr_fmt去自定义fmt打印前缀。比如
#define pr_fmt(fmt) KBUILD_MODNAME ":" fmt定义自己模块名字作为前缀 - 这里XXX也是代表打印级别0~7,比如pr_err/pr_warn/pr_info...
如下图所示:

dump_stack和WARN_ON
dump_stack()
dump_stack是Linux Kernel支持的一个对当前stack回溯的函数,它会打印出来当前线程调用到该函数的堆栈信息。
这个函数在想查看当前函数有哪些入口路径时,是非常好用的。
WARN_ON(1)
但是有的平台是不支持dump_stack的,这种情况下,可以加入WARN_ON(1)函数,这个函数本来是Linux内核做警告的,但是在警告的同时会打印backtrace,这就可以被我们用来回溯堆栈。
使用GDB对内核进行源码级调试
可以使用gdb进行vmlinux内核源码的源码级别的调试,虽然一般情况下源码级别的调试没有什么鸟用。
在本机Qemu虚拟机上调试
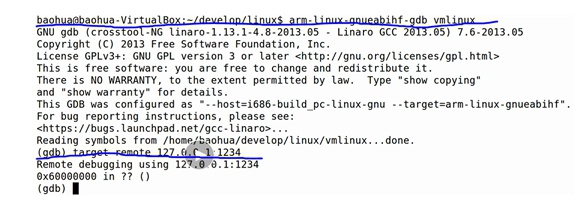
① 启动本地qemu:

② 使用gdb加载vmlinux:
arm-linux-gnueabihf-gdb vmlinux③ 使用gdb远程连接调试端口:(本机)
target remote 127.0.0.1:1234
④ 使用gdb命令开始调试,比如b、c、n等等等等
通过仿真器调试开发板
① 准备仿真器环境,仿真器网口连接PC,调试口通过USB连接板子的JTAG
② 使用gdb加载vmlinux:
arm-linux-gnueabihf-gdb vmlinux③ 使用gdb远程连接调试端口:
target remote IP:port这里IP、port是仿真器通过网线链接电脑时,仿真器上写死的IP和port。这样就能用gdb通过仿真器去链接开发板做调试了。
Tips:
这里有一个很尬尴的问题,一直没有搞明白:
既然都有仿真器了,那就直接用仿真器界面、按钮、鼠标啥的去直接通过Jtage口调试板子就好了
为啥还非要gdb呢,是不是因为非正版的没有相关UI界面。。。
④ 使用gdb命令开始调试,比如b、c、n等等等等
内核KO模块源码级调试
对以KO形式通过insmod去加载的内核模块进行源码级别调试,比直接对内核进行源码级别调试的操作要稍微复杂一些。
因为Kernel启动之后各个符号地址就都确定了,但是对于以KO形式加载的内核模块而言,是在insmod加载时才确定的符号地址的(代码段/数据段)。
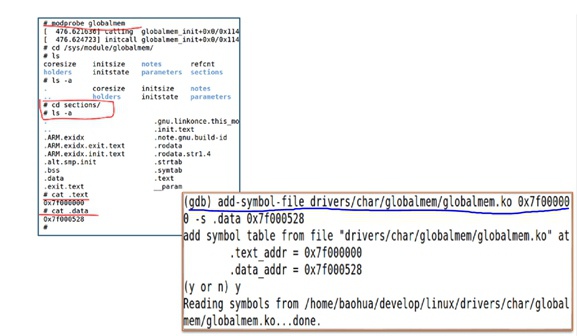
① 先做insmod:modprobe globalmem
② 进入sections:cd /sys/module/globalmem/sections/
③ 查看text段:cat .text
④ 查看data段:cat .data
⑤ 加载vmlinux符号表:arm-linux-gnueabihf-gdb vmlinux
⑥ 用gdb远程连接:target remote IP:port
⑦ 用add symbole加载代码段和数据段符号表:add-symbol-file drivers/char/globalmem/globalmem.ko 0x7f000000 -s .data 0x7f000528
使用KGDB对内核进行源码级调试
TODO...
使用仿真器对内核进行源码级调试
Trace32仿真器
这是SOC芯片调试中最常用的一种仿真器,是劳德巴赫开发的,既有ARM Lisence的也有Intel Lisence的,区别主要就是仿真器使用的头不一样的。T32的价位是比较贵的,但是一些购物网站上也有很多几百块钱很便宜的那种。。。
TODO...
DS-5仿真器
它与Trace32不同的地方在于,它是ARM公司自己研发的专门针对ARM平台的,是ARM平台上最专业的仿真器,既能用来调试功能又能用来分析性能,极其强大,价位也非常昂贵。
TODO...
Code Viser仿真器
一款不太常用的仿真器,没有T32好用,但是好处就是便宜。。。
内核OOPS与Panic错误
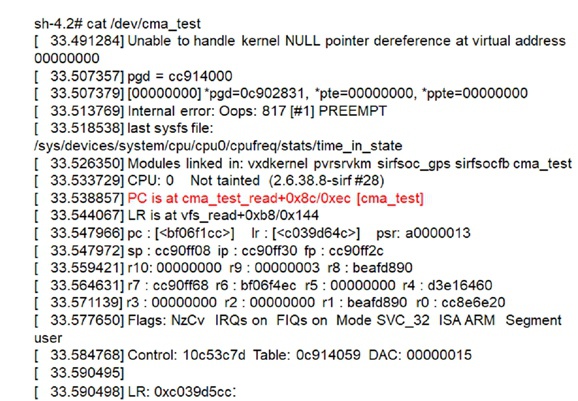
OOPS
oops打印信息基本如下所示,这里面显示了Kernel崩溃的原因,PC指针、LR指针、崩溃时当前栈帧下r0~r15(64位上是x0~x31/w0~w31)每个寄存器值,以及下面还有一段没有打出来的崩溃时的堆栈信息等等。。。
OOPS解析
对于这个东西的解析,其实我们是可以分不同情况的:
这里可能是没开这个功能,也可能是没有触发Kernel Panic掉,总之是没有sysdump文件(见下一章节)可供crash tool/trace32工具加载和分析,这时遵循的步骤大概是:
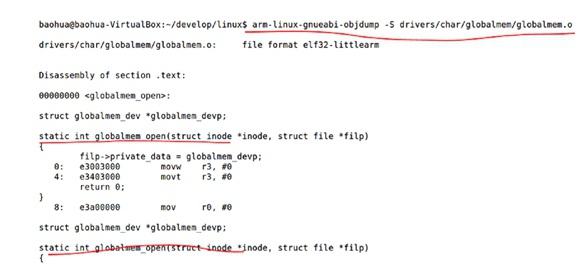
- 用
objdump -S/-D xxxx命令去解析出错函数所在的.O文件(或者极端情况下去解析整个vmlinux符号表文件),生成.S汇编文件 - 根据出错信息中提供的PC/LR的值、以及后面“函数内偏移/整体位置”等信息,找到.S汇编文件中出错的位置
- 根据出错时汇编语句、当前栈帧下r0~r15寄存器的值,去推断出错的“可能”原因
- 根据猜测的出错原因,结合C代码,去推断C代码中流程或者传参可能存在的异常
Tips:
另外,如果只单纯去查看某地址对应的C代码行,也可以简单使用addr2line这个命令来做
这里分析起来就会非常简单,不需要再单独去解析.O或者vmlinux文件了,直接使用CrashTool或者Trace32 Simulator去加载符号表、sysdump文件即可进行分析。对于sysdump以及如何分析见下一章节描述。
Panic
这里需要提到的是,OOPS与Panic虽然都会打印内核backtrace等信息,但区别是OOPS不一定会Panic,有时OOPS只是打印信息中止外设等一些不重要进程,还不至于让整个Kernel直接崩溃掉。
如下条件下的OOPS会导致内核Panic掉:
- OOPS发生在中断上下文中,而不是发生在进程上下文
- CONFIG_PANIC_ON_OOPS参数设置成y,同时CONFIG_PANIC_ON_OOPS_VALUE参数设置成1,即发生OOPS一律Panic掉
Tips:
通常我们在debug阶段,都会将panic_on_oom打开,这是合理的
一是容易帮助工程师定位问题
二是oops可能会导致很长时间之后内核panic掉了,此时已经不是第一现场了,再去追溯问题点不那么容易
Panic解析
对于Panic的解析,是需要sysdump文件的,具体也见下面一章节的描述。
SYSDUMP内核内存镜像转储
这里我们把它叫成了sysdump只是局部的叫法,其它地方可能也把它叫做其它的名字。
生成原理
虽然名字各不相同,但统一的是它的实现原理:将当前正在运行的Linux Kernel的内存镜像保存下来,并添加头部信息生成一个后者一系列文件。具体实现见sysdump原理
解析分析
一般对于生成的sysdump文件,我们有两种办法去解析:
- ① 使用RedHat的Crash Tool,详情见工具-稳定性分析-CrashTool
- ② 使用Trace32 Simulator,详情见工具-稳定性分析-Trace32
它们的基本原理差不多,区别:一个是shell命令行格式的,一个是有UI图形界面的(跟Trace32直接调试内核一样的界面)
工程 - 串口打印
我们常用的uart串口工具有如下几个,这些工具都被用于抓u-boot和kernel的串口打印信息。
minicom
minicom这个工具是ubuntu系统自带的一个串口工具,通常是不需要安装的,我们在ubuntu linux上做开发时用起来十分方便。
一般情况下,可能需要根据板子uart口的波特率设置一下该工具的波特率,默认是115200.
连接串口命令如下:
sudo minicom -D /dev/ttyUSB0 //或者ttyUSB1,看串口被枚举到哪个端口上grabserial
grabserial这个工具比较好的一个点是,它在输出打印的时候,会使用电脑时间给每一条log增加时间戳打印前缀。
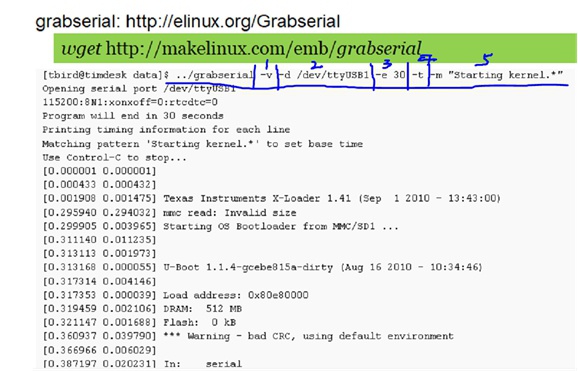
以上每一条打印都有前后两个时间戳,其中:
- 第一个时间戳是:grabserial收到当前这一条log的时间
- 第二个时间戳是:grabserial收到当前这一条log与上一条log的时间差值
以上可以看出,其实grabserial对于我们做开机启动优化其实是很有帮助的,能够看出某一个阶段耗时大概是多少。
工程 - 内核Debug选项
Linux内核中有很多Debug选项,这些Debug选项中的大部分是平时不开启的。当需要debug某一个阶段或者模块时,我们只需要找到对应的Debug选项,并且将它开启即可。
Tips:
这些内核Debug选项,其实大都是可以通过bootargs参数带入内核中的
比如,当我们调试系统的suspend/resume时,我们可以开启如下选项:
- no_console_suspend
- CONFIG_PM_DEBUG
再比如,有些东西不开启Debug选项是非常难调试的,如在spinlock、irq、softirq中无意调用了可sleep的函数,如果不开启内核相应的Debug选项是很难定位的,这时有一些选项(如果硬件条件允许,主要是内存和CPU利用率等)我们一般在系统debug阶段会是一直开启着的:
- CONFIG_DEBUG_ATOMIC_SLEEP
再比如,对于slab类的内核内存踩踏,我们通常用的Debug选项是:
- CONFIG_SLUB_DEBUG
- CONFIG_SLUB_DEBUG_ON
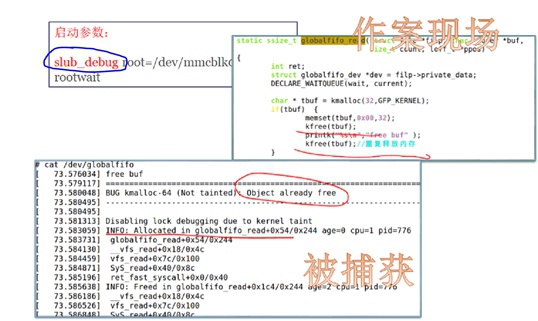
关于slab分配器的debug详细描述见文章内存管理-内存分配器-slub调试
再比如,对于slab类的内核内存泄漏,我们需要开启的Debug选项是:
- CONFIG_HAVE_DEBUG_KMEMLEAK
- CONFIG_DEBUG_KMEMLEAK
工程 - RCU STALL
RCU是内核中比较难的一个锁🔒,这个东西是为了改造“临界区”的读写性能而创造的,“读”优先级会高于“写”,只有当读的进行都完成之后,先等待一个grace period宽限期(其它core都做了一个context switch之后),然后写才会进行更新。
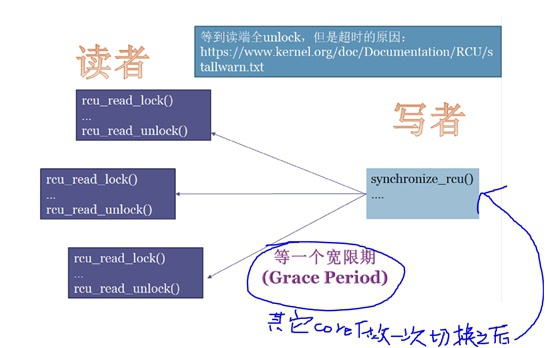
RCU读可以有多个线程并行发生,但是写只能有一个线程串行发生。但是在写之前,会先做copy->write的动作,然后等grace period过了可以进行写之后只需要update时切换struct的指针即可,这样速度很快,又不耽误读操作。
RCU STALL检测就是利用其它core都做了一次调度这个grace period,当发现一直无法完成写update时就提示RCU STALL,也就是说提醒我们出现了某个core上让调度无法完成的动作,比如:锁中断、锁调度、RT进程一直占用等等。。。
关于RCU具体详细解读见文章内核锁-RCU
工程 - Lockup Detector
关于这个Lockup Detector和它能检测的softlock、hardlockup具体描述,见文章【概述】-Linux内核同步-内核锁
参考文档