内存管理:内存分配器-slub
slab是基于buddy的内存二次分配器的统称,它目前有三种实现算法,分别是slab、slub、slob,并且,依据它们各自的分配算法,在适用性方面会有一定的侧重。
slub内存分配器是目前linux kernel中最常用的分配器,它基于slab分配器改造而来,保留了slab的思想、大部分的数据结构、完整的API接口,摒弃了slab的着色机制、优化了slab的管理数据结构,比slab更加简单和高效,目前已经取代slab分配器成为kernel的默认分配器。
SOURCE CODE TREE
在linux内核中,可以从下面几个文件找一下slab相关的source code
- /kernel/mm/slab.h : 三个分配器本地公共头文件
- /kernel/mm/slab_common.c : 三个分配器公共源码抽取
- /kernel/mm/slab.c : slab分配器源码,最早的分配器,是其它实现的基础
- /kernel/mm/slub.c : slub分配器源码,当前主流首选分配器
- /kernel/mm/slob.c : slob分配器源码,主要适用于内存有限的嵌入式设备
- /kernel/include/linux/slab.h : 三个分配器公共头文件,提供对外接口
- /kernel/include/linux/slab_def.h : slab分配器对外头文件
- /kernel/include/linux/slub_def.h : slub分配器对外头文件
- /kernel/include/linux/mm_types.h : 定义了page结构体
MECHANISM
基本思想
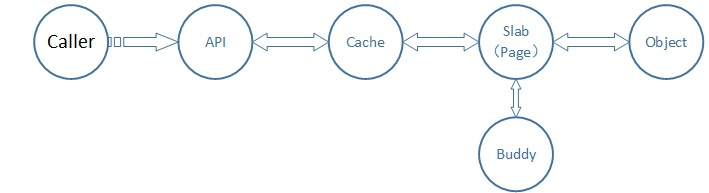
① slab分配器构建于buddy分配器之上进行二次分配,旨在对从buddy申请的内存页进行二次管理,并对外提供粒度更小的内存。
② buddy分配出的1个或者n个连续的物理页框叫做一个slab,它被分割成了大小一致且数目固定的object,这些object即slab分配器对外提供的内存单元。
③ 同时slab又被按照内核使用object时的不同用途、object的不同大小进行更详细的归类分组,这些相互独立的类叫做slab cache,它负责管理此类的所有slab。所有的slab cache用一个全局链表串联在一起,方便管理和遍历。
Tips:
实际上slab能分配的object最大值远远大于1个page,但是这并不妨碍我们对于slab是二次分配器的理解。因为内核使用小粒度的内存要更加频繁。
数据结构
在精读别人代码时,首先了解原理,然后个人建议最好还是从数据结构入手,搞清楚数据结构之间的包含、指向、引用等关系,然后再逐步看流程会轻松一些.
网上有很多文章把slab这里的关键数据结构归为如下3个:
但是个人认为还需要加上第4个:
因为正是page结构体为slab内存管理这个feature提供了可以复用的字段,使得以上三个结构体对object的管理能够实现
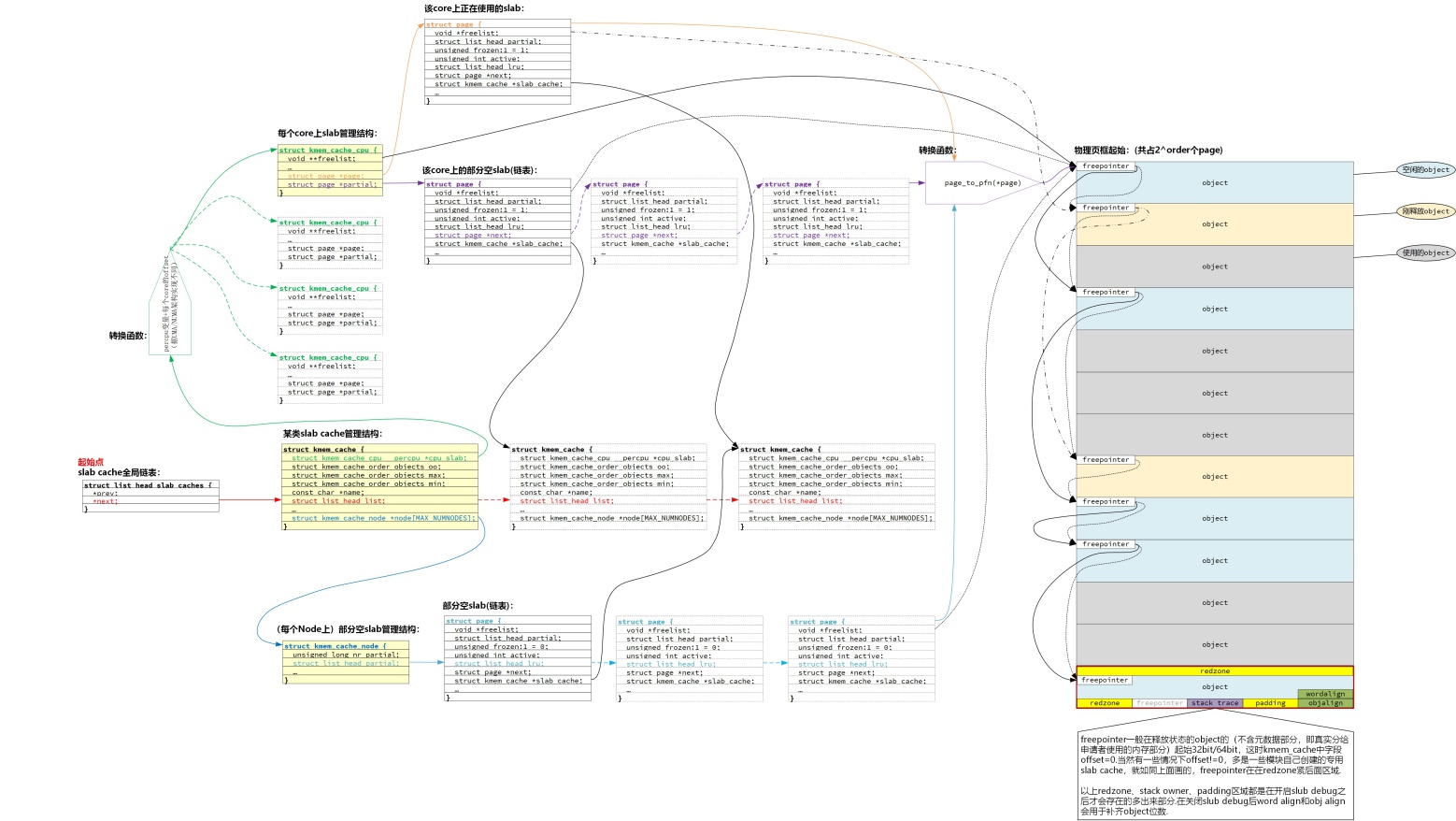
① slab_cache全局链表是一个双向链表,上面挂载了所有的kmem_cache节点,包含专用的kmem_cache(比如TCPv6、ext4_inode_cache等)、通用kmem_cache(比如kmalloc-8、kmalloc-64等),可以通过遍历该链表来找到任意一个kmem_cache. 每个kmem_cache,包含两个关键数据结构:
- kmem_cache_cpu:cpu上正在使用的slab
- kmem_cache_node:备用的部分空slab链表
② kmem_cache_cpu是CPU上当前使用的slab page,它是percpu变量,即每个core上一个、互不干扰,对于特定core上的kmem_cache_cpu结构也包含2个关键数据结构:
- page指向该core正在使用的slab page,通过page结构体字段复用,管理对应物理页框
- partial指向一个链表,该链表挂载了core上的一些部分空slab page,这些slab的特点是使用率高、可能只剩下最后1个object待分配出去了
③ kmem_cache_node是备用的部分空slab链表(当然也可能有全空的),它使用关键数据结构partial串连起来所有部分空slab page,每个slab page也是page结构体复用。
① kmem_cache->align计算
kmem_cache->align = calculate_alignment(flags, align, size);
比如,boot时boot_kmem_cache与boot_kmem_cache_node对应三个输入参数值是:
<1> flags=SLAB_HWCACHE_ALIGN,即0x00002000=2^13次幂
<2> align=ARCH_KMALLOC_MINALIGN:即8bytes
<3> size=该slab cache中需要包含的object类型的大小,用sizeof去计算得出
Tips:
其中ARCH_KMALLOC_MINALIGN定义是:
如果有些arch将DMA内存也用于kmalloc分配的话,值就是L1_CACHE_BYTES,这个宏是在arch/${ARCH}/include/asm/cache.h中定义的。比如arm64中是128。其它情况是__alignof__(unsigned long long),即8bytes
函数calculate_alignment(flags, align, size)的整个计算过程代码见源码/mm/slab_common.c,可以基本概括为:
<1> 如果需要按照硬件cacheline对齐,那么就将align对齐到1个cacheline,或者1/2个cacheline,或者1/4个cacheline,但是不小于ARCH_SLAB_MINALIGN(它也是根据arch定义,默认值8bytes),最后将align转换为该arch上指针大小的整数倍。
<2> 如果不需要按照硬件cacheline对齐,那么就按照align对齐,最后将align也转换为该arch上指针大小的整数倍,但是也不小于ARCH_SLAB_MINALIGN。
Tips:
arm是要求按照硬件cacheline对齐的
② kmem_cache->reserved计算
if (need_reserve_slab_rcu && (s->flags & SLAB_TYPESAFE_BY_RCU))
s->reserved = sizeof(struct rcu_head);这里need_reserve_slab_rcu的定义:
#define need_reserve_slab_rcu \
(sizeof(((struct page *)NULL)->lru) < sizeof(struct rcu_head))在page结构体定义中(见前面)lru与rcu_head共享一个union数据结构单元,它们定义分别如下:
struct list_head {
struct list_head *next, *prev;
};
...
struct callback_head {
struct callback_head *next;
void (*func)(struct callback_head *head);
} __attribute__((aligned(sizeof(void *))));
#define rcu_head callback_head所以,从这里看这个need_reserve_slab_rcu通常是不成立的,也即除非特殊arch架构的芯片上,通常reserved==0
③ kmem_cache->size计算
if (!calculate_sizes(s, -1))
goto error;这个东西计算的比较复杂,calculate_sizes函数前半段大部分代码就是在计算这个size值,其计算路径中,逐一去判断条件并包含了object、redzone、track、padding、kasan等等,还有一系列的对齐调整,在此不再赘述,详情看代码calculate_sizes函数实现.
④ kmem_cache->offset计算
size_t size = s->object_size;
...
size = ALIGN(size, sizeof(void *));
...
if ((flags & SLAB_RED_ZONE) && size == s->object_size)
size += sizeof(void *);
...
if (((flags & (SLAB_TYPESAFE_BY_RCU | SLAB_POISON)) ||
s->ctor)) {
s->offset = size;
...
}可见这是在满足以上几个条件下的offset,而通常情况offet==0的
⑤ kmem_cache->oo和kmem_cache->min计算
s->oo = oo_make(order, size, s->reserved);
s->min = oo_make(get_order(size), size, s->reserved);bit0~bit15这低16位表示object大小,bit16以上表示的是该slab cache中需要申请的page的order
if (forced_order >= 0)
order = forced_order;
else
order = calculate_order(size, s->reserved);order值是根据object大小计算得出的,order值(0、1、2、3...)代表连续页框数目(4K、8K、16K、32K...),也即该slab申请到的连续地址空间,或者简单叫做该slab的大小. 计算order值原则是:在能分配出空间的前提下,尽量减少内存的"内碎片",避免空间浪费又兼顾分配效率. 具体分析见下面算法分析部分.
⑥ kmem_cache->flags和kmem_cache->allocflags获取
s->flags = kmem_cache_flags(s->size, flags, s->name, s->ctor);这个flags表示slab cache功能属性、内存页面属性等等,最开始被置为default值0(不开debug时),创建slab cache时根据各种属性去设置
s->allocflags = 0;
if (order)
s->allocflags |= __GFP_COMP;
if (s->flags & SLAB_CACHE_DMA)
s->allocflags |= GFP_DMA;
if (s->flags & SLAB_RECLAIM_ACCOUNT)
s->allocflags |= __GFP_RECLAIMABLE;这个allocflags表示该slab页面属性,在申请page页(申请slab页)时根据page页属性修改
⑦ kmem_cache->min_partial计算
set_min_partial(s, ilog2(s->size) / 2);每个NUMA节点上需要保留的partial slab数目,这个值会介于MIN_PARTIAL=5和MAX_PARTIAL=10之间
Tips:
MIN_PARTIAL是partial slab数目最小值,数目达到这个值的partial全空闲slab也不会被释放回buddy,但是会被memory shrink回收
MAX_PARTIAL是partial slab数目最大值,数目超过这个值的将触发memory shrink
⑧ kmem_cache->cpu_partial计算
#ifdef CONFIG_SLUB_CPU_PARTIAL
if (!kmem_cache_has_cpu_partial(s))
s->cpu_partial = 0;
else if (s->size >= PAGE_SIZE)
s->cpu_partial = 2;
else if (s->size >= 1024)
s->cpu_partial = 6;
else if (s->size >= 256)
s->cpu_partial = 13;
else
s->cpu_partial = 30;
#endif其中kmem_cache_has_cpu_partial中指定如果开启slab debug则cpu partial链表上slab最大数目是0,相当于关闭状态
① 每个object上freepoint计算
start = page_address(page);
...
for_each_object_idx(p, idx, s, start, page->objects) {
setup_object(s, page, p);
if (likely(idx < page->objects))
set_freepointer(s, p, p + s->size);
else
set_freepointer(s, p, NULL);
}通过以上将每个object虚拟地址(不含metadata的)赋值给上一个object的freepointer,在这个slab page上形成了一个链表
② page->freelist的计算
start = page_address(page);
page->freelist = fixup_red_left(s, start);将page的freelist指向被映射的连续物理页框上的第一个object的虚拟地址(不含metadata的)
③ page->objects和page->inuse计算
page->objects = oo_objects(oo);
...
page->inuse = page->objects; 这里inuse被直接初始化为该页上objects数量,但是inuse表示已经使用的
后面立即会随着第一个object被分配给kmem_cache_node而被修改成已经使用的objects数量:
page->inuse = 1;
page->frozen = 0;
kmem_cache_node->node[node] = n; //直接分配出第一个object给了全局的boot_kmem_cache_node
分配完一个object之后,该slab page就直接挂在了kmem_cache_node->node->partial链表上了
① kmem_cache_node->nr_partial计算
static inline void
__add_partial(struct kmem_cache_node *n, struct page *page, int tail)
{
n->nr_partial++;
if (tail == DEACTIVATE_TO_TAIL)
list_add_tail(&page->lru, &n->partial);
else
list_add(&page->lru, &n->partial);
}
在把slab page挂接到kmem_cache_node->partial链表上时+1
① kmem_cache_cpu->tid计算:
static void init_kmem_cache_cpus(struct kmem_cache *s)
{
int cpu;
for_each_possible_cpu(cpu)
per_cpu_ptr(s->cpu_slab, cpu)->tid = init_tid(cpu);
}
这里只是在初始化的时候将kmem_cache_cpu->tid置为它所在的cpuid值.
每当分配一个object出去,该值+TID_STEP如下:
static void *___slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node,
unsigned long addr, struct kmem_cache_cpu *c)
{
...
c->tid = next_tid(c->tid);
...
}
...
#ifdef CONFIG_PREEMPT
#define TID_STEP roundup_pow_of_two(CONFIG_NR_CPUS)
#else
#define TID_STEP 1
#endif
static inline unsigned long next_tid(unsigned long tid)
{
return tid + TID_STEP;
}流程图
TODO...
TODO...
TODO...
TODO...
API
重点API列表
| API Name | Description |
|---|---|
| F | Sanity checks on (enables SLAB_DEBUG_CONSISTENCY_CHECKS Sorry SLAB legacy issues) |
| Z | Red zoning |
TODO...
TODO...
性能瓶颈
① 锁
- slab_lock/slab_unlock
- kmem_cache_node->list_lock
② rcu
③ cmpxchg
order值选取的大小会影响到slab上object数量,进而会影响到分配器的效率。
高的order值会减少访问kmem_cache_node的次数,减少锁的使用次数。
算法抽象
解决“鸡生蛋、蛋生鸡的问题”
问题的产生 =》
分配器初始化时,第一个kmem_cache和第一个kmem_cache_node这俩“管理结构”所使用的内存也需要从它们对应的kmem_cache、kmem_cache_node这两类不同的slab cache中分配object,但是,此时还没有建立以上两个对应的slab cache,于是这就产生了矛盾。
问题的解决 =》
① 首先在.init.data段内定义两个静态变量:
static __initdata struct kmem_cache boot_kmem_cache,
boot_kmem_cache_node;
② 然后初始化两个变量保存kmem_cache和kmem_cache_node管理结构
③ 再然后用这两个管理结构创建kmem_cache和kmem_cache_node两个slab cache
④ 再然后再从这两个slab cache中各自分配出1个object来
⑤ 最后将开始的两个静态变量的内容对应copy到以上2个object中
⑥ 最终由于开始申请的两个静态变量是位于.init.data段,在启动使用过后会被释放掉
以上就完成了slab的bootstrap自启动流程,解决了第一个slab object也必须从slab分配的问题。
解决“slab内部碎片导致内存浪费的问题”
问题的产生 =》
分配的slab大小不一定是object大小的整数倍,最后很可能产生一个无法利用的“碎片”空间.
问题的解决 =》
calculate_order函数尽量减小该碎片空间,它的实现思路是:在固定object大小的条件下,通过迭代去寻找一个能让object数量和slab大小达到"平衡"的order值。这个"平衡"指的是在该slab分配完object后能让剩余内存空间(此时已经不够分配一个object)<某个标准值,比如在内核4.x代码中给出的标准值范围是slab大小的1/16、1/8、1/4. 这里之所以选取这三个数,应该是考虑到了地址对齐以及一个页面能够容纳的object数量.
① 为了能上面的迭代有一个起点,必须事先指定一个slub_max_order,根据object大小计算出其数量max_objects,并取max_objects与根据cpu核心数量计算出的object数量min_objects两个之间的最小值
② 然后利用该最小值去逐一适配从order=0到order=slub_max_order之间的slab,直到找到一个slab它的order值能满足内存剩余标准值范围后终止(从1/16迭代到1/8再迭代到1/4)
③ 如果最后order都不满足,则说明需要减小object数量,将它减1后重复上面迭代过程,直到将该最小值减小到1.
④ 如果减小到1还是找不到合适的slab,说明slub_max_order选取的不合适,连一个object也容纳不了,需要用MAX_ORDER替代它去分配一个slab给这个object.
⑤ 如果再分配不出就只能报错返回了.
Tips:
slub_max_order的选取:PAGE_ALLOC_COSTLY_ORDER = 3,这是一个经验值,通常被认为是介于系统有、无回收页面压力之间的一个值.
解决“近似的slab cache频繁申请带来的性能问题”
解决“内存紧急时尽量释放内存的问题”
参考文档